On October 1st, 2024, OpenAI introduced assist for fine-tuning GPT-4o with imaginative and prescient capabilities. This lets you customise a model of GPT-4o particularly for duties the place the bottom mannequin would possibly battle, comparable to precisely figuring out objects in advanced scenes or recognizing delicate visible patterns. Whereas GPT-4o demonstrates spectacular common imaginative and prescient capabilities, fine-tuning lets you improve its efficiency for area of interest or specialised purposes.
The Roboflow crew has experimented extensively with fine-tuning fashions, and we’re excited to share how we skilled GPT-4o, and how one can practice your individual GPT-4o imaginative and prescient mannequin for object detection. Object detection is a job that the bottom GPT-4o mannequin finds difficult with out fine-tuning.
💡
On this information, we’ll display learn how to fine-tune GPT-4o utilizing a taking part in card dataset. Whereas seemingly simple, this dataset presents a number of vital challenges for imaginative and prescient language fashions: dozens of object lessons, a number of objects in every picture, class names consisting of a number of phrases, and a excessive diploma of visible similarity between objects.

Dataset construction
GPT-4o expects knowledge in a selected format, as proven under. <IMAGE_URL> must be changed with an HTTP hyperlink to your picture, whereas <USER_PROMPT> and <MODEL_ANSWER> symbolize the person’s question concerning the picture and the anticipated response, respectively. Relying on the vision-language job, these could possibly be, for instance, a query concerning the picture and its corresponding reply within the case of Visible Query Answering (VQA).
{
'messages': [
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'user',
'content': <USER_PROMPT>
},
{
'role': 'user',
'content': [
{
'type': 'image_url',
'image_url': {'url': <IMAGE_URL>}
}
]
},
{
"function": "assistant",
"content material": <MODEL_ANSWARE>
}
]
}
Drawing from our expertise with different VLMs, we determined to format the <USER_PROMPT> and <MODEL_ANSWER> in the identical manner as for PaliGemma.
<USER_PROMPT>consists of the key phrase detect adopted by a semicolon-separated listing of the lessons you need to find.
detect 10 of golf equipment ; 10 of diamonds ; 10 of hearts ; 10 of spades ...<MODEL_ANSWER>is a semicolon-separated listing of detection definitions. Every definition contains the bounding field geometry description adopted by the identify of the detected class. The field coordinates are organized within the ordery_min, x_min, y_max, x_max, then normalized, multiplied by1024, and rounded to integers.
<loc0161><loc0145><loc0640><loc0451> 9 of spades ; <loc0120><loc0485><loc0556><loc0744> 10 of spades ; <loc0477><loc0459><loc0848><loc0664> jack of spades ; <loc0295><loc0667><loc0676><loc0896> queen of spades ; <loc0600><loc0061><loc0978><loc0330> king of spadesIf you wish to be taught extra about PaliGemma and the detection format it helps, try our YouTube tutorial:
Pull dataset from Roboflow
Happily, you do not have to manually convert your object detection dataset to this format. Any detection dataset on Roboflow Universe can now be exported within the format required for GPT-4o imaginative and prescient fine-tuning. You may automate this whole course of utilizing roboflow SDK.
pip set up roboflowfrom roboflow import Roboflow rf = Roboflow(api_key=<ROBOFLOW_API_KEY>) workspace = rf.workspace("roboflow-jvuqo")
mission = workspace.mission("poker-cards-fmjio")
model = mission.model(3)
dataset = model.obtain("openai")Add a coaching file
After you have your dataset within the appropriate format and dimension, it is time to add it. We’ll use the OpenAI SDK for this.
pip set up openaiSubsequent, create an occasion of the OpenAI consumer, passing in your OPENAI_API_KEY, which you could find in your OpenAI account settings:
from openai import OpenAI consumer = OpenAI(api_key=<OPENAI_API_KEY>)The ultimate step is to offer the paths to the recordsdata containing your coaching and validation subsets and add them utilizing the consumer we initialized earlier. As soon as uploaded, every file will probably be assigned a novel ID that we’ll use shortly when submitting the fine-tuning job.
training_file_upload_response = consumer.recordsdata.create(
file=open(f"{dataset.location}/_annotations.practice.jsonl", "rb"),
objective="fine-tune"
)
training_file_upload_response # FileObject(
# id='file-OeucFR8fKMF68qdJ9yCSESPv',
# bytes=548592,
# created_at=1727908593,
# filename='_annotations.practice.jsonl',
# object='file',
# objective='fine-tune',
# standing='processed',
# status_details=None
# ) validation_file_upload_response = consumer.recordsdata.create(
file=open(f"{dataset.location}/_annotations.legitimate.jsonl", "rb"),
objective="fine-tune"
)
validation_file_upload_response # FileObject(
# id='file-uo8nWSYWdo51SF9XodisEn6K',
# bytes=30011,
# created_at=1727908594,
# filename='_annotations.legitimate.jsonl',
# object='file',
# objective='fine-tune',
# standing='processed',
# status_details=None
# )Coaching
Lastly, we’re prepared to begin coaching. It is vital to notice that for now, imaginative and prescient fine-tuning can solely be carried out on the gpt-4o-2024-08-06 mannequin. To make it simpler to determine our mannequin later, it is useful so as to add a suffix, which will probably be appended to the checkpoint identify of our skilled mannequin.
fine_tuning_response = consumer.fine_tuning.jobs.create(
training_file=training_file_upload_response.id,
validation_file=validation_file_upload_response.id,
suffix="poker-cards",
mannequin="gpt-4o-2024-08-06"
)
fine_tuning_response # FineTuningJob(
# id='ftjob-2UYwRHDQXjm1qBG88RqCEeRB',
# created_at=1727908609,
# error=Error(code=None, message=None, param=None),
# fine_tuned_model=None,
# finished_at=None,
# hyperparameters=Hyperparameters(
# n_epochs='auto',
# batch_size='auto',
# learning_rate_multiplier='auto'
# ),
# mannequin='gpt-4o-2024-08-06',
# object='fine_tuning.job',
# organization_id='org-sLGE3gXNesVjtWzgho17NkRy',
# result_files=[],
# seed=667206240,
# standing='validating_files',
# trained_tokens=None,
# training_file='file-OeucFR8fKMF68qdJ9yCSESPv',
# validation_file='file-uo8nWSYWdo51SF9XodisEn6K',
# estimated_finish=None,
# integrations=[],
# user_provided_suffix='poker-cards'
# )As soon as coaching begins, we will observe its progress within the fine-tuning dashboard.
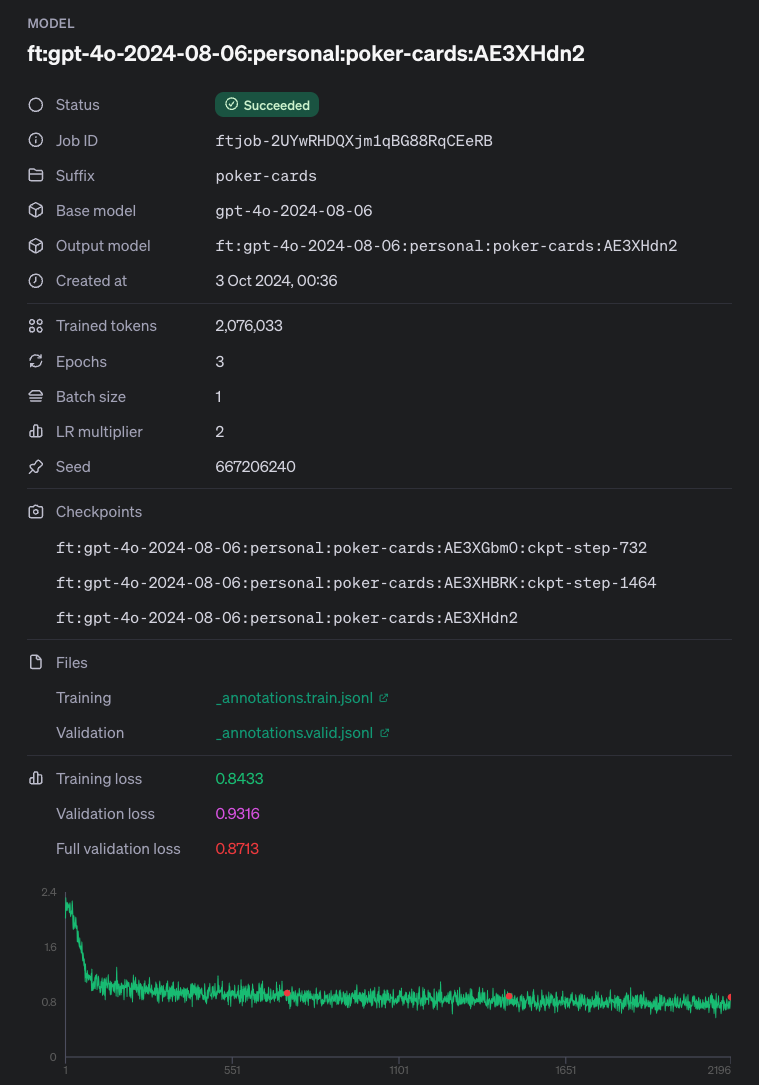
Checking Coaching Standing
After you have began a fine-tuning job, it could take a while to finish. Your job could also be queued behind different jobs in theour system, and coaching a mannequin can take minutes or hours relying on the mannequin and dataset dimension. Nevertheless, you possibly can verify the standing of your coaching job at any time within the UI or through an API name:
status_response =consumer.fine_tuning.jobs.retrieve(fine_tuning_response.id)
status_response # FineTuningJob(
# id='ftjob-2UYwRHDQXjm1qBG88RqCEeRB',
# created_at=1727908609,
# error=Error(code=None, message=None, param=None),
# fine_tuned_model='ft:gpt-4o-2024-08-06:private:poker-cards:AE3XHdn2',
# finished_at=1727913545,
# hyperparameters=Hyperparameters(
# n_epochs=3,
# batch_size=1,
# learning_rate_multiplier=2
# ),
# mannequin='gpt-4o-2024-08-06',
# object='fine_tuning.job',
# organization_id='org-sLGE3gXNesVjtWzgho17NkRy',
# result_files=['file-Kk8dqKdelvneesBc9uVWfLdZ'],
# seed=667206240,
# standing='succeeded',
# trained_tokens=2076033,
# training_file='file-OeucFR8fKMF68qdJ9yCSESPv',
# validation_file='file-uo8nWSYWdo51SF9XodisEn6K',
# estimated_finish=None,
# integrations=[],
# user_provided_suffix='poker-cards'
# )Utilizing fine-tuned mannequin
As soon as coaching is accomplished efficiently — the fine-tuning job standing within the response above adjustments to succeeded — you possibly can run predictions utilizing your mannequin. The identifier of your fine-tuned mannequin can be discovered within the standing response below status_response.fine_tuned_model. The construction of the messages used to question your mannequin is sort of an identical to a dataset entry: it features a system immediate, a person immediate, and the picture to which the person immediate refers.
messages = [
{
'role': 'system',
'content': 'You are a helpful assistant.'
},
{
'role': 'user',
'content': 'detect 5 of spades;6 of spades;7 of spades;8 of spades'
},
{
'role': 'user',
'content': [
{
'type': 'image_url',
'image_url': {'url': <IMAGE_URL>}
}
]
}
] completion = consumer.chat.completions.create(
mannequin=status_response.fine_tuned_model,
messages=messages
) completion.decisions[0].message # ChatCompletionMessage(
# content material='<loc0360><loc0268><loc0636><loc0377> 5 of spades;<loc0328><loc0344><loc0667><loc0480> 6 of spades;<loc0280><loc0433><loc0756><loc0623> 7 of spades;<loc0232><loc0607><loc0857><loc0882> eight of spades',
# refusal=None,
# function='assistant',
# function_call=None,
# tool_calls=None
# )Parsing Mannequin Predictions
Fashions like GPT-4o and their open-source alternate options, comparable to PaliGemma and Florence-2, generate a sequence of tokens as output. These tokens require post-processing to acquire a significant illustration of the detected objects’ positions.
VLMs work by encoding each the picture and the immediate right into a shared embedding area, permitting them to cause concerning the relationship between visible and textual info.
As talked about earlier, we utilized a illustration according to the one proposed by PaliGemma, enabling us to course of the output equally. An instance of the uncooked output from our fine-tuned GPT-4o mannequin is proven under:
completion.decisions[0].message.content material # <loc0360><loc0268><loc0636><loc0377> 5 of spades;<loc0328><loc0344><loc0667><loc0480> 6 of spades;<loc0280><loc0433><loc0756><loc0623> 7 of spades;<loc0232><loc0607><loc0857><loc0882> eight of spades
The supervision bundle supplies ready-to-use utilities that permit you to parse strings within the format supported by standard fashions, convert them into the extra conventional illustration utilized in object detectors, after which visualize them.
import requests
import supervision as sv
from PIL import Picture picture = Picture.open(requests.get(<IMAGE_URL>, stream=True).uncooked)
detections = sv.Detections.from_lmm(
lmm=sv.LMM.PALIGEMMA,
outcome=completion.decisions[0].message.content material,
resolution_wh=picture.dimension
) box_annotator = sv.BoxAnnotator(color_lookup=sv.ColorLookup.INDEX)
label_annotator = sv.LabelAnnotator(color_lookup=sv.ColorLookup.INDEX) annotated_image = picture.copy()
annotated_image = box_annotator.annotate(
scene=picture,
detections=detections
)
annotated_image = label_annotator.annotate(
scene=annotated_image,
detections=detections
)
supervision.Value
The price of GPT-4o fine-tuning is predicated on the variety of coaching tokens, calculated because the variety of tokens within the coaching dataset multiplied by the variety of coaching epochs. Within the context of vision-language fashions like GPT-4o, a token represents a basic unit of knowledge, which is usually a phrase within the textual content or a portion of a picture.
Picture inputs are first tokenized primarily based on picture dimension, after which priced on the identical per-token charge as textual content inputs. The bigger your coaching dataset or the longer the coaching course of, the upper the associated fee will probably be. At present, the unit worth is $25 / 1M coaching tokens.
OpenAI does not cost you for the tokens within the validation set.
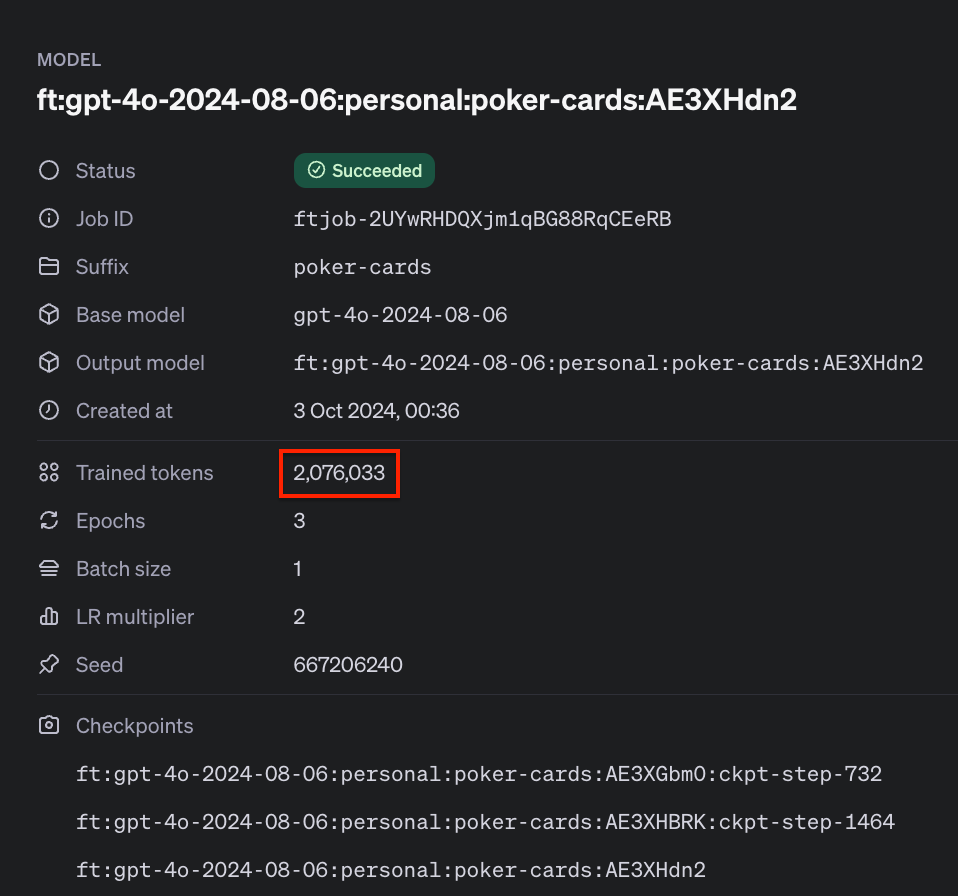
You could find the whole variety of coaching tokens in your coaching job within the Advantageous-tuning dashboard and within the response that checks the standing of your coaching job. It was round 2M in our case, so the estimated price of coaching this mannequin was about $50.
The variety of tokens within the coaching dataset is determined by many elements that may be optimized, such because the variety of pictures within the dataset, the decision of the pictures, and, within the case of object detection, the format of the textual content storing the bounding field coordinates, which can include extra or fewer textual content tokens. It’s due to this fact attainable that the identical coaching impact could possibly be achieved utilizing even a number of instances fewer tokens, and thus scale back the coaching price.

Issues to Take into account
Whereas fine-tuning GPT-4o presents thrilling prospects, it is important to pay attention to sure elements earlier than diving in.
Censorship
Throughout our experimentation with OpenAI GPT-4o fine-tuning throughout varied imaginative and prescient duties, we encountered an sudden hurdle with OCR. We selected the CATMuS Medieval dataset, which comprises pictures of medieval manuscripts and their corresponding transcribed textual content. Nevertheless, upon launching the fine-tuning job, we obtained the next message:> The job failed resulting from an invalid coaching file. Too many pictures had been skipped resulting from moderation. Please be certain that your pictures don’t include content material that violates our utilization coverage.
Value
As demonstrated in our instance, coaching a mannequin on a dataset of roughly 800 pictures proved to be fairly costly. Compared, utilizing the identical dataset, we may practice a convolutional mannequin like YOLO or perhaps a VLM like Florence-2 at no cost utilizing Google Colab. Alternatively, OpenAI lets you course of 1M tokens at no cost every single day. Sufficient to experiment a bit!
Privateness
Advantageous-tuning GPT-4o requires importing your knowledge to OpenAI’s servers. This raises privateness considerations, particularly for delicate knowledge. It is essential to bear in mind that your knowledge will probably be processed and saved by OpenAI. Moreover, even after coaching is full, the fine-tuned mannequin stays accessible solely via the OpenAI API, limiting your management and possession over the mannequin.
Conclusions
Advantageous-tuning GPT-4o for object detection lets you improve its efficiency for particular duties, leveraging its understanding of each visible and textual info. Nevertheless, contemplate the prices and limitations earlier than beginning.
Whereas promising, devoted fashions like YOLOv10 are doubtless simpler for accuracy-critical duties. GPT-4o’s cloud dependency requires a steady web connection and introduces latency, hindering manufacturing use and real-time purposes.
Typically, different fashions or open-source VLMs present a less expensive, privacy-conscious, and versatile answer. As the sphere evolves, anticipate developments in fine-tuning and accessibility. Keep knowledgeable and consider the trade-offs to harness the potential of VLMs in your pc imaginative and prescient wants.



