Lately, the sector of machine studying has made vital advances in numerous drawback sorts, from picture recognition to pure language processing.
Nonetheless, most of those fashions function on knowledge from a single modality, corresponding to pictures, textual content, or speech. In distinction, real-world knowledge usually comes from a number of modalities, corresponding to pictures and textual content, video and audio, or sensor knowledge from a number of sources.
To deal with this problem, researchers have developed multimodal machine studying fashions that may deal with knowledge from a number of modalities, unlocking new potentialities for clever programs.
On this weblog submit, we’ll discover the challenges and alternatives of multimodal machine studying, and talk about the totally different architectures and methods used to sort out multimodal pc imaginative and prescient challenges.
What’s Multimodal Deep Studying?
Multimodal Deep Studying is a subset of deep studying that offers with the fusion and evaluation of knowledge from a number of modalities, corresponding to textual content, pictures, video, audio, and sensor knowledge. Multimodal Deep Studying combines the strengths of various modalities to create a extra full illustration of the information, main to raised efficiency on varied machine studying duties.
Historically, machine studying fashions have been designed to work on knowledge from a single modality, corresponding to picture classification or speech recognition. Nonetheless, in the actual world, knowledge usually comes from a number of sources and modalities, making it extra advanced and tough to research. Multimodal Deep Studying goals to beat this problem by integrating info from totally different modalities to generate extra correct and informative fashions.
What’s the Objective of Multimodal Deep Studying?
The first purpose of Multimodal Deep Studying is to create a shared illustration area that may successfully seize complementary info from totally different modalities. This shared illustration can then be used to carry out varied duties, corresponding to picture captioning, speech recognition, and pure language processing.
Multimodal Deep Studying fashions usually encompass a number of neural networks, every specialised in analyzing a specific modality. The output of those networks is then mixed utilizing varied fusion methods, corresponding to early fusion, late fusion, or hybrid fusion, to create a joint illustration of the information.
Early fusion includes concatenating the uncooked knowledge from totally different modalities right into a single enter vector and feeding it to the community. Late fusion, then again, includes coaching separate networks for every modality after which combining their outputs at a later stage. Hybrid fusion combines components of each early and late fusion to create a extra versatile and adaptable mannequin.
How Does Multimodal Studying Work?
Multimodal deep studying fashions are usually composed of a number of unimodal neural networks, which course of every enter modality individually. As an example, an audiovisual mannequin could have two unimodal networks, one for audio and one other for visible knowledge. This particular person processing of every modality is named encoding.
As soon as unimodal encoding is finished, the knowledge extracted from every modality should be built-in or fused. There are a number of fusion methods accessible, starting from easy concatenation to consideration mechanisms. Multimodal knowledge fusion is a vital issue for the success of those fashions. Lastly, a “determination” community accepts the fused encoded info and is educated on the duty at hand.
Normally, multimodal architectures encompass three elements:
- Unimodal encoders encode particular person modalities. Normally, one for every enter modality.
- A fusion community that mixes the options extracted from every enter modality, throughout the encoding section.
- A classifier that accepts the fused knowledge and makes predictions.
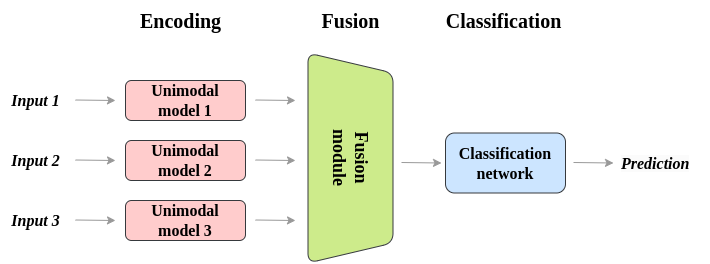
Encoding Stage
The encoder extracts options from the enter knowledge in every modality and converts them into a typical illustration that may be processed by subsequent layers within the mannequin. The encoder is often composed of a number of layers of neural networks that use nonlinear transformations to extract more and more summary options from the enter knowledge.
The enter to the encoder can consist of knowledge from a number of modalities, corresponding to pictures, audio, and textual content, that are usually processed individually. Every modality has its personal encoder that transforms the enter knowledge right into a set of characteristic vectors. The output of every encoder is then mixed right into a single illustration that captures the related info from every modality.
One in style strategy for combining the outputs of the person encoders is to concatenate them right into a single vector. One other strategy is to make use of consideration mechanisms to weigh the contributions of every modality primarily based on their relevance to the duty at hand.
The general purpose of the encoder is to seize the underlying construction and relationships between the enter knowledge from a number of modalities, enabling the mannequin to make extra correct predictions or generate new outputs primarily based on this multimodal enter.
Fusion Module
The fusion module combines info from totally different modalities (e.g., textual content, picture, audio) right into a single illustration that can be utilized for downstream duties corresponding to classification, regression, or technology. The fusion module can take varied varieties relying on the particular structure and activity at hand
One widespread strategy is to make use of a weighted sum of the modalities’ options, the place the weights are realized throughout coaching. One other strategy is to concatenate the modalities’ options and move them via a neural community to be taught a joint illustration.
In some instances, consideration mechanisms can be utilized to be taught which modality needs to be attended to at every time step.
Whatever the particular implementation, the purpose of the fusion module is to seize the complementary info from totally different modalities and create a extra strong and informative illustration for the downstream activity. That is particularly essential in functions corresponding to video evaluation, the place combining visible and audio cues can vastly enhance efficiency.
Classification
The classification module takes the joint illustration generated by the fusion module and makes use of it to make a prediction or determination. The precise structure and strategy used within the classification module can differ relying on the duty and kind of knowledge being processed.
In lots of instances, the classification module takes the type of a neural community, the place the joint illustration is handed via a number of totally related layers earlier than the ultimate prediction is made. These layers can embrace non-linear activation capabilities, dropout, and different methods to assist stop overfitting and enhance generalization efficiency.
The output of the classification module depends upon the particular activity at hand. For instance, in a multimodal sentiment evaluation activity, the output can be a binary determination indicating whether or not the textual content and picture enter is constructive or adverse. In a multimodal picture captioning activity, the output is likely to be a sentence describing the content material of the picture.
The classification module is often educated utilizing a supervised studying strategy, the place the enter modalities and their corresponding labels or targets are used to optimize the parameters of the mannequin. This optimization is usually performed utilizing gradient-based optimization strategies corresponding to stochastic gradient descent or its variants.
In evaluation, the classification module performs a vital position in multimodal deep studying by taking the joint illustration generated by the fusion module and utilizing it to make an knowledgeable determination or prediction.
Multimodal Studying in Laptop Imaginative and prescient
Lately, multimodal studying has emerged as a promising strategy to sort out advanced pc imaginative and prescient duties by combining info from a number of modalities corresponding to pictures, textual content, and speech.
This strategy has enabled vital progress in a number of areas, together with:
- Visible query answering;
- Textual content-to-image technology, and;
- Pure language for visible reasoning.
On this part, we’ll discover how multimodal studying fashions have revolutionized pc imaginative and prescient and made it potential to attain spectacular leads to difficult duties that beforehand appeared not possible. Particularly, we’ll dive into the workings of three in style makes use of of multimodal architectures within the pc imaginative and prescient area: Visible Query Answering (VQA), Textual content-to-Picture Era, and Pure Language for Visible Reasoning (NLVR).
Visible Query Answering (VQA)
Visible Query Answering (VQA) includes answering questions primarily based on visible enter, corresponding to pictures or movies, utilizing pure language. VQA is a difficult activity that requires a deep understanding of each pc imaginative and prescient and pure language processing.
Lately, VQA has seen vital progress on account of using deep studying methods and architectures, significantly the Transformer structure. The Transformer structure was initially launched for language processing duties and has proven nice success in VQA.
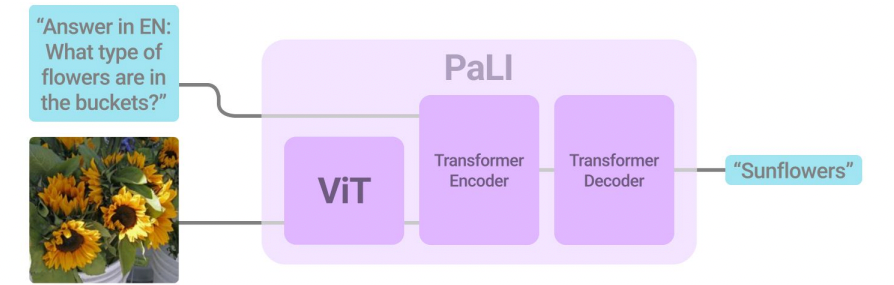
Probably the most profitable fashions for VQA is the PaLI (Pathways Language and Picture mannequin) mannequin developed by Google Analysis in 2022. PaLI structure makes use of an encoder-decoder Transformer mannequin, with a large-capacity ViT element for picture processing.
Textual content-to-Picture Era
In text-to-image technology, a machine studying mannequin is educated to generate pictures primarily based on textual descriptions. The purpose is to create a system that may perceive pure language and use that understanding to generate visible content material that precisely represents the that means of the enter textual content.
The 2 most up-to-date and profitable fashions are DALL-E and Secure Diffusion.
DALL-E is a text-to-image technology mannequin developed by OpenAI, which makes use of a mixture of a transformer-based language mannequin and a generative neural community structure. The mannequin takes in a textual description and generates a picture that satisfies the outline. DALL-E can generate all kinds of advanced and artistic pictures, corresponding to a snail fabricated from harps and a collage of a pink tree kangaroo in a area of daisies.
One of many key improvements in DALL-E is using a discrete latent area, which permits the mannequin to be taught a extra structured and controllable illustration of the generated pictures. DALL-E is educated on a big dataset of image-text pairs, and the mannequin is optimized utilizing a variant of the VAE loss operate referred to as the Gumbel-Softmax trick.
The Secure Diffusion structure is a latest approach for producing high-quality pictures primarily based on textual content prompts. Diffusion makes use of a diffusion course of, which includes iteratively including noise to an preliminary picture after which progressively eradicating the noise.
By controlling the extent of noise and the variety of iterations, Diffusion can generate numerous and high-quality pictures that match the enter textual content immediate.
The important thing innovation in Diffusion is using a diffusion course of that permits for secure and numerous picture technology. As well as, diffusion makes use of a contrastive loss operate to encourage the generated pictures to be numerous and distinct from one another. Diffusion has achieved spectacular leads to text-to-image technology, and it might probably generate high-quality pictures that intently match the enter textual content prompts.

Pure Language for Visible Reasoning (NLVR)
Pure Language for Visible Reasoning (NLVR) goals to judge the flexibility of fashions to grasp and purpose about pure language descriptions of visible scenes. On this activity, a mannequin is given a textual description of a scene and two corresponding pictures, certainly one of which is according to the outline and the opposite not. The target of the mannequin is to determine the proper picture that matches the given textual description.
NLVR requires the mannequin to grasp advanced linguistic constructions and purpose about visible info to make the proper determination. The duty includes a wide range of challenges, corresponding to understanding spatial relations, recognizing objects and their properties, and understanding the semantics of pure language.
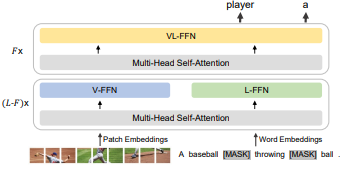
The present state-of-the-art on the NLVR activity is reached by BEiT-3. It’s a transformer-based mannequin that has been pre-trained on large-scale datasets of pure pictures and texts, corresponding to ImageNet and Conceptual Captions.
BEiT-Three is designed to deal with each pure language and visible info and is able to reasoning about advanced linguistic constructions and visible scenes.
The structure of BEiT-Three is just like that of different transformer-based fashions, corresponding to BERT and GPT, however with some modifications to deal with visible knowledge. The mannequin consists of an encoder and a decoder, the place the encoder takes in each the visible and textual inputs and the decoder produces the output.
Challenges Constructing Multimodal Mannequin Architectures
Multimodal Deep Studying has revolutionized the way in which we strategy advanced knowledge evaluation duties, corresponding to picture and speech recognition. Nonetheless, working with knowledge from a number of modalities poses distinctive challenges that should be addressed to attain optimum efficiency.
On this part, we’ll talk about a few of the key challenges related to Multimodal Deep Studying.
Alignment
Alignment is the method of making certain that knowledge from totally different modalities are synchronized or aligned in time, area, or some other related dimension. The dearth of alignment between modalities can result in inconsistent or incomplete representations, which may negatively influence the efficiency of the mannequin.
Alignment might be significantly difficult in eventualities the place the modalities are acquired at totally different occasions or from totally different sources. A first-rate instance of a state of affairs the place alignment is a tough problem to unravel is in video evaluation. Aligning the audio with the visible info might be difficult as a result of latency launched by the information acquisition course of. Equally, in speech recognition, aligning the audio with the corresponding transcription might be tough on account of variations in talking charges, accents, and background noise.
A number of methods have been proposed to handle the alignment problem in multimodal machine studying fashions. As an example, temporal alignment strategies can be utilized to align the information in time by estimating the time offset between modalities. Spatial alignment strategies can be utilized to align knowledge in area by figuring out corresponding factors or options in numerous modalities.
Moreover, deep studying methods, corresponding to consideration mechanisms, can be utilized to robotically align the information throughout the mannequin coaching course of. Nonetheless, every alignment approach has its strengths and limitations, and the selection of alignment methodology depends upon the particular drawback and the traits of the information.
Co-learning
Co-learning includes collectively studying from a number of modalities to enhance the efficiency of the mannequin. In co-learning, the mannequin learns from the correlations and dependencies between the totally different modalities, which may result in a extra strong and correct illustration of the underlying knowledge.
Co-learning requires designing fashions that may deal with the heterogeneity and variability of the information from totally different modalities, whereas additionally figuring out the related info that may be shared throughout modalities. That is difficult. Moreover, co-learning can result in the issue of adverse switch, the place studying from one modality negatively impacts the efficiency of the mannequin on one other modality.
To deal with the co-learning problem in multimodal machine studying fashions, a number of methods have been proposed. One strategy is to make use of joint illustration studying strategies, corresponding to deep canonical correlation evaluation (DCCA) or cross-modal deep metric studying (CDML), which purpose to be taught a shared illustration that captures the correlations between the modalities. One other strategy is to make use of consideration mechanisms that may dynamically allocate the mannequin’s sources to essentially the most informative modalities or options.
Co-learning remains to be an energetic analysis space in multimodal machine studying, and there are lots of open questions and challenges to be addressed, corresponding to the way to deal with lacking modalities or the way to incorporate prior data into the educational course of.
Translation
Translation includes changing the information from one modality or language to a different. For instance, translating speech to textual content, textual content to speech, or picture to textual content.
Multimodal machine studying fashions that require translation should take into consideration the variations within the construction, syntax, and semantics between the supply and goal languages or modalities. Moreover, they need to be capable to deal with the variability within the enter knowledge, corresponding to totally different accents or dialects, and adapt to the context of the enter.
There are a number of approaches to handle the interpretation problem in multimodal machine studying fashions. One widespread strategy is to make use of neural machine translation (NMT) fashions, which have proven nice success in translating textual content from one language to a different. NMT fashions will also be used to translate speech to textual content or vice versa by coaching on paired audio-text knowledge. One other strategy is to make use of multimodal fashions that may be taught to map knowledge from one modality to a different, corresponding to image-to-text or speech-to-text translation.
Nonetheless, translating between modalities or languages is a difficult activity. The efficiency of the interpretation fashions closely depends upon the standard and measurement of the coaching knowledge, the complexity of the duty, and the supply of computing sources.
Fusion
Fusion includes combining info from totally different modalities to decide or prediction. There are other ways to fuse knowledge, together with early fusion, late fusion, and hybrid fusion.
Early fusion includes combining the uncooked knowledge from totally different modalities on the enter degree. This strategy requires aligning and pre-processing the information, which might be difficult on account of variations in knowledge codecs, resolutions, and sizes.
Late fusion, then again, includes processing every modality individually after which combining the outputs at a later stage. This strategy might be extra strong to variations in knowledge codecs and modalities, however it might probably additionally result in the lack of essential info.
Hybrid fusion is a mixture of each early and late fusion approaches, the place some modalities are fused on the enter degree, whereas others are fused at a later stage.
Selecting the suitable fusion methodology is vital to the success of a multimodal machine studying mannequin. The fusion methodology should be tailor-made to the particular drawback and the traits of the information. Moreover, the fusion methodology should be designed to protect essentially the most related info from every modality and keep away from the introduction of noise or irrelevant info.
Conclusion
Multimodal Deep Studying is an thrilling and quickly evolving area that holds nice potential for advancing pc imaginative and prescient and different areas of synthetic intelligence.
Via the combination of a number of modalities, together with visible, textual, and auditory info, multimodal studying permits machines to understand and interpret the world round them in ways in which have been as soon as solely potential for people.
On this submit, we highlighted three key functions of multimodal studying in pc imaginative and prescient: Visible Query Answering, Textual content-to-Picture Era, and Pure Language for Visible Reasoning.
Whereas there are challenges related to multimodal studying, together with the necessity for big quantities of coaching knowledge and the issue of fusing info from a number of modalities, latest advances in deep studying fashions have led to vital enhancements in efficiency throughout a spread of duties.



