Metrics surrounding the efficiency of your laptop imaginative and prescient mannequin – from precision to recall to mAP – kind the idea of many necessary selections one has to make throughout the strategy of constructing a mannequin. Utilizing mannequin metrics, you’ll be able to reply questions like:
- Is my mannequin prepared for manufacturing?
- Is the false constructive charge too excessive?
- How does the most recent iteration of my mannequin examine to earlier ones?
Utilizing Roboflow’s open-source CVevals bundle, you’ll be able to consider object detection and classification fashions hosted on Roboflow.
CVevals compares the bottom fact in your dataset – the annotations you could have added to photographs – with predictions your mannequin yields on photographs in your validation dataset and makes use of that data to calculate analysis metrics in your dataset.
On this information, we’re going to point out find out how to use CVevals to guage a retail shelf object detection dataset. By the tip of this tutorial, we can have metrics on precision, recall, F1, and a confusion matrix exhibiting how our mannequin performs on our validation dataset. We’ll additionally evaluate, briefly, find out how to run an analysis on a classification dataset.
We are able to use these metrics to decide on whether or not a mannequin is prepared for manufacturing and, if it isn’t, present knowledge on what we could have to do to enhance our mannequin to arrange it for manufacturing.
With out additional ado, let’s get began!
Step 1: Set up CVevals
The CVevals bundle is bundled in a Github repository. This repository accommodates many examples exhibiting find out how to consider various kinds of fashions, from Roboflow fashions to state-of-the-art zero-shot fashions corresponding to Grounding DINO and CLIP. For this information, we’ll give attention to the instance for evaluating a Roboflow mannequin.
To put in CVevals, run the next strains of code:
git clone https://github.com/roboflow/evaluations.git
cd evaluations
pip set up -r necessities.txt
pip set up -e .This code will obtain the bundle and set up it in your native machine. Now we’re prepared to begin evaluating our mannequin!
Step 2: Configure the Analysis
Suppose we’re working with a retail shelfobject detection mannequin that finds empty areas on a shelf and areas the place a product is current. We wish to know what number of false positives the mannequin returns on our validation dataset. We additionally need to have the ability to visualize the bounding bins returned by our mannequin. We are able to accomplish each of those duties utilizing CVevals.
CVevals works in three phases:
- You specify a supply from which to load your floor fact knowledge;
- You specify a supply from which to load mannequin predictions (on this instance, we’ll use Roboflow);
- The bottom fact knowledge is in contrast with predictions to calculate analysis metrics.
On this instance, we are able to use the examples/roboflow_example.py script. This script masses knowledge from Roboflow and runs your mannequin in your validation dataset.
To make use of the script, you will want your:
- Roboflow API key
- Workspace ID
- Mannequin ID
- Mannequin model quantity
You may discover ways to retrieve these values in our documentation.
We additionally want to decide on a location the place we’ll retailer the info we’ll use in our analysis. We suggest storing the info in a brand new folder. For this information, we’ll retailer knowledge on this path:
/Customers/james/cvevals/retail-shelf-data/If the folder doesn’t exist already, will probably be created.
Now we’re able to run our analysis!
Step 3: Run the Analysis
To run the analysis, use the next command:
python3 examples/roboflow_example.py --eval_data_path=<path_to_eval_data>
--roboflow_workspace_url=<workspace_url>
--roboflow_project_url=<project_url>
--roboflow_model_version=<model_version>
--model_type=object-detectionSubstitute the values you famous within the final part within the angle brackets above. Then, run the command.
If you’re working with a single-label classification dataset, set the --model_type= worth to classification. If you’re working with a multi-label classification dataset, use --model_type=multiclass.
This code will: (i) retrieve your floor fact knowledge, on this case from Roboflow; (ii) run inference on every picture in your validation set; (ii) return prediction outcomes. As inference runs on every picture, a message will probably be printed to the console like this:
evaluating picture predictions towards floor fact <image_name>The period of time the analysis script takes will rely on what number of validation photographs you could have in your dataset.
After the analysis is completed, you will notice key metrics printed to the console, like this:
Precision: 0.7432950191570882
Recall: 0.8083333333333333
f1 Rating: 0.7744510978043913There may even be a brand new folder in your laptop referred to as `output` that accommodates two subfolders:
matrices: Confusion matrices for every picture in your dataset.photographs: Your photographs with floor fact and mannequin predictions plotted onto the picture.
There’s a particular matrix referred to as combination.png which displays the efficiency of your mannequin throughout all photographs in your dataset. Here’s what the confusion matrix appears to be like like for our retail shelf instance:
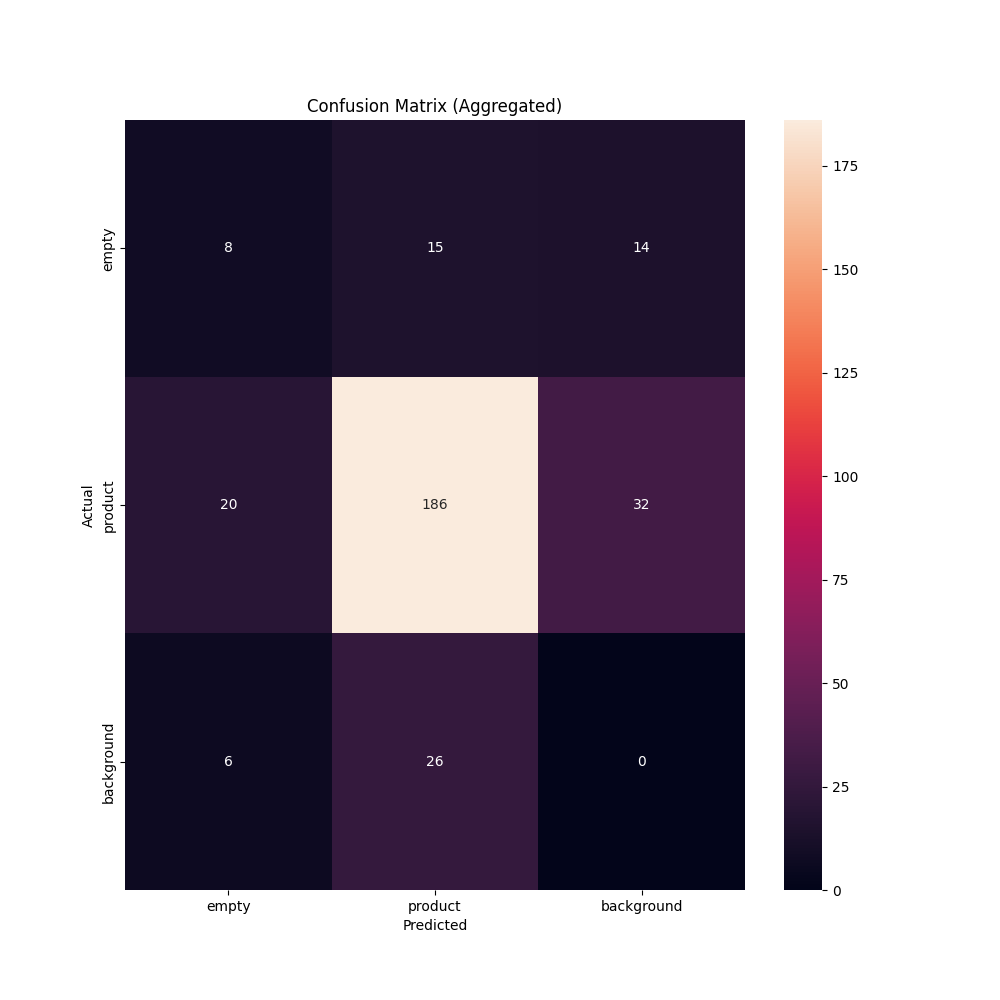
We are able to use this confusion matrix to grasp true and false constructive charges throughout our dataset and confirm whether or not the values point out our mannequin is prepared for manufacturing. From the matrix above, we are able to make determinations on whether or not the false constructive charge is just too excessive for any class. Whether it is, we are able to use that data to return to our mannequin and plan a technique for enchancment.
For example, if a specific class has a excessive false constructive charge, it’s possible you’ll wish to add extra consultant knowledge for a given class then retrain your mannequin. With a modified mannequin, you’ll be able to run your analysis once more to see how your adjustments impacted mannequin efficiency.
Let’s open up one of many photographs within the output/photographs listing to visualise our mannequin predictions:
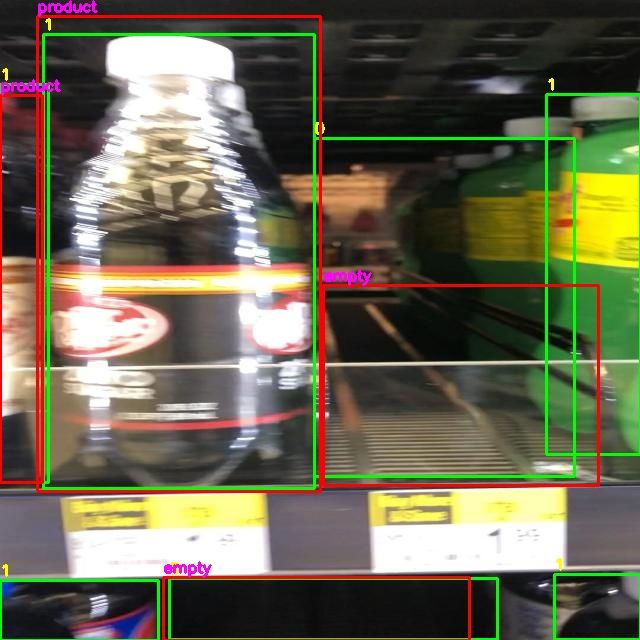
We are able to use these photographs to visualise how our mannequin performs.
Floor fact – your annotations – are in inexperienced bounding bins. Mannequin predictions are in displayed inside crimson bins.
From the above picture, for instance, we are able to see that our mannequin has recognized lots of the areas within the picture, but it surely missed two on the underside shelf. If it is advisable to dive deep into mannequin efficiency, these photographs is usually a helpful reference. For example, in the event you see there are a lot of false positives, you’ll be able to evaluate photographs to visualise cases of false positives.
Conclusion
On this information, we’ve calculated precision, recall, and F1 metrics related to an object detection mannequin. We’ve got additionally computed confusion matrices we are able to use to higher perceive how our mannequin performs.
With this data, we are able to make selections in regards to the readiness of a mannequin for manufacturing. If a mannequin doesn’t carry out in addition to anticipated, you should use that data to make a plan about what to do subsequent.
CVevals has a variety of different options, too, corresponding to permitting you to:
- Examine completely different confidence ranges to grasp which one is finest to be used in manufacturing;
- Consider the efficiency of varied zero-shot fashions (Grounding DINO, CLIP, BLIP, and extra) in your dataset, and;
- Examine prompts for zero-shot fashions.
To seek out out extra in regards to the different options accessible within the library, try the undertaking README.



