We’re typically informed that knowledge is the spine that drives the event of highly effective and sturdy fashions. And that is definitely true – knowledge is the uncooked materials that we feed into our algorithms, serving to them to study, adapt, and make predictions. Nevertheless, not simply any knowledge will suffice.
Excessive-quality, clear knowledge is what really makes the distinction in terms of coaching pc imaginative and prescient fashions. “Rubbish in, rubbish out” is an adage as outdated as knowledge processing itself, and it reminds us that the standard of our enter knowledge is simply as essential, if no more so.
On this experiment, we sought to discover whether or not downsizing the dataset with out dropping important accuracy was achievable. By fastidiously pruning over 10ok pictures that had been both outliers, blurry, or duplicates, we managed to cut back the dataset measurement by practically 26% whereas sustaining a mAP rating of 76.5% with Ultralytics YOLOv8, in comparison with 79% on the unique dataset.
So, is that this 3% drop in mAP value it? Let’s take into account some elements:
- Effectivity: Decreasing the dataset measurement by such a major margin might result in extra environment friendly coaching and decrease computational prices. This might be notably invaluable in eventualities the place assets are constrained.
- High quality Management: By eliminating ambiguous or poor-quality pictures, the dataset could develop into extra constant, resulting in a mannequin that performs extra robustly in particular real-world eventualities.
- Sensible Affect: A 3% drop in mAP is perhaps acceptable relying on the applying. If the mannequin is being utilized in a context the place absolute prime efficiency isn’t important, the trade-off is perhaps fairly favorable.
- Potential Overfitting: Decreasing the presence of noisy or irrelevant knowledge would possibly even assist in stopping overfitting, permitting the mannequin to generalize higher to unseen knowledge.
Nevertheless, it is important to think about the precise necessities of the duty at hand:
- If the applying calls for the best attainable accuracy and each proportion level is significant, this discount may not be appropriate.
- If there are different elements comparable to the necessity for sooner prototyping, decrease prices, or a deal with higher-quality knowledge, this 3% trade-off might certainly be thought-about successful.
The worth of this method is determined by a fancy interaction of things together with effectivity, software necessities, and the standard of the info itself. In our case, the slight lower in mAP appears to be an affordable trade-off for a extra refined and environment friendly dataset. Nevertheless, as with many points of machine studying, the ‘proper’ method is determined by the precise context and targets of the challenge.
Introduction
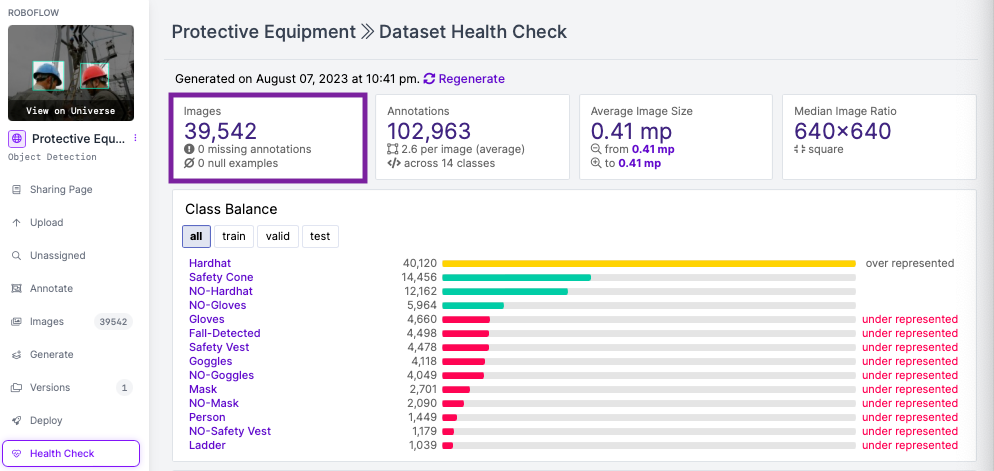
On this weblog submit, we’ll be exploring an intricate but sensible method to knowledge administration for environment friendly mannequin coaching. We’ll exhibit how one can obtain the identical mannequin accuracy with much less knowledge by cleansing our dataset successfully. We’ll use a complete instance utilizing a private protecting gear dataset of over 39,00Zero pictures and YOLOv8 object detection mannequin, showcasing using libraries comparable to roboflow, ultralytics and fastdup.


By the tip of this submit, we are going to prune over 10,500 pictures which are blurry, duplicates, and outlier pictures lowering our dataset by a major quantity. With a smaller clear dataset, you’ll be able to cut back labeling prices and computation prices whereas sustaining the accuracy of your mannequin.
Figuring out and Addressing Suboptimal Information
To optimize a dataset, we must always determine and deal with suboptimal knowledge. This consists of:
- Duplicates or extremely related pictures: These might result in overfitting and bias. Eradicating them ensures dataset variety.
- Outlier pictures: These are pictures which are considerably completely different from nearly all of pictures in our dataset. They may fluctuate when it comes to shade distribution, object orientation, or presence of surprising parts. Outliers could distract the mannequin in the course of the coaching part and decrease its efficiency.
- Blurry pictures: Low-quality pictures cut back accuracy as they do not present clear options.
- Darkish or vivid pictures: Excessive lighting situations hinder function identification and studying.
With this understanding, we are able to now define the steps we’ll comply with on this information:
- Set up Libraries
- Obtain Dataset
- Practice on Unique Information
- Analyzing the Dataset with Fastdup
- Determine invalid, duplicate, and outlier pictures
- Take away duplicates, outliers, and blurry pictures
- Practice and Re-deploy
Step 1: Set up Libraries
We’ll make the most of roboflow for managing and downloading dataset, fastdup for analyzing and cleansing the dataset, and YOLOv8 for coaching the mannequin.
!pip -q set up roboflow fastdup ultralyticsStep 2: Downloading the Dataset
Roboflow is a complete software for managing pc imaginative and prescient workflows. It gives a collection of options, together with knowledge labeling, versioning, and a library of public datasets often known as “Roboflow Universe”. This software simplifies knowledge acquisition and administration to your tasks.
To obtain a dataset, use the next code:
roboflow.login()
rf = Roboflow()
challenge = rf.workspace("roboflow-ngkro").challenge("protective-equipment-s3hzi")
dataset = challenge.model(1).obtain("yolov8")You’ll be able to additional refine your datasets utilizing Roboflow’s options just like the “Filter by Tag” preprocessing software.
Step 3: Practice on Unique Information
Earlier than we clear the dataset, we are able to prepare the mannequin on the unique dataset to benchmark its efficiency. That is optionally available however might present insightful context. We use the YOLOv8 mannequin for coaching with pre-trained weights for 100 epochs and reached 0.79 on mAP50. You’ll be able to strive the deployed pre-trained mannequin right here.
mannequin = YOLO('yolov8n.pt')
mannequin.prepare(knowledge=dataset.location + '/knowledge.yaml', epochs=100, imgsz=640)Step 4: Analyzing the Dataset with Fastdup
To make sure that our mannequin isn’t overfitting because of duplicate or very related pictures, we use the Fastdup library to research our dataset. We analyze the coaching, testing, and validation datasets individually.
fd_train = fastdup.create(work_dir="./prepare/", input_dir=dataset.location + '/prepare/pictures')
fd_train.run()
fd_test = fastdup.create(work_dir="./take a look at/", input_dir=dataset.location + '/take a look at/pictures')
fd_test.run()
fd_valid = fastdup.create(work_dir="./legitimate/", input_dir=dataset.location + '/legitimate/pictures')
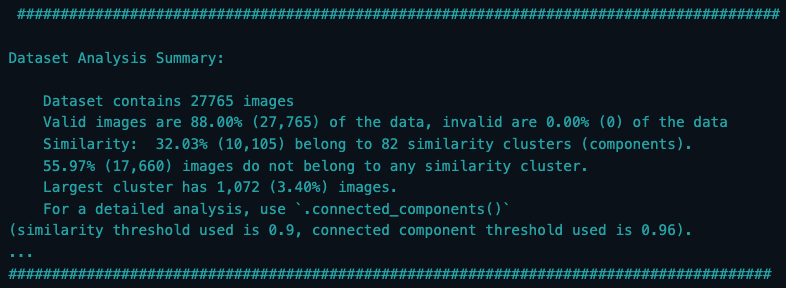
fd_valid.run()This may output an in depth evaluation abstract as proven under, offering details about the similarities inside your dataset. You may study the entire variety of pictures, what number of of these are thought-about legitimate, the proportion of similarity, the quantity and proportion of outliers, and extra.
Step 5: Determine Invalid, Duplicate, and Outlier Pictures
Duplicate Pictures
FastDup permits us to visually examine duplicate or near-duplicate pictures in our dataset. By figuring out and eradicating these, we are able to cut back the dimensions of our dataset with out negatively affecting the range of our knowledge.
We create stories for every dataset utilizing:
fd_train.vis.duplicates_gallery()
fd_test.vis.duplicates_gallery()
fd_valid.vis.duplicates_gallery()
Utilizing the stories, we are able to visualize the duplicate pictures. We first discover the linked elements in our picture dataset. The connected_components() operate returns a DataFrame with details about the linked elements within the dataset and we group the linked elements. These elements characterize clusters of comparable pictures in our dataset. Then, we course of clusters for every set.
cluster_images_to_keep_train, list_of_duplicates_train = process_clusters(clusters_df_train)
cluster_images_to_keep_test, list_of_duplicates_test = process_clusters(clusters_df_test)
cluster_images_to_keep_valid, list_of_duplicates_valid = process_clusters(clusters_df_valid)
Outlier Pictures
Then, we are able to determine outlier pictures. Outliers are pictures which are dissimilar to nearly all of pictures in our dataset. Nevertheless, this does not essentially imply that these pictures are problematic or irrelevant; they may simply be distinct in some points (comparable to shade distribution, texture, object presence, and many others.), resulting in their high-distance classification. Utilizing a selected threshold, we are able to determine these outliers and take away them from our dataset after verifying, making certain our mannequin isn’t distracted by these situations.
outlier_df_train = fd_train.outliers()
list_of_outliers_train = outlier_df_train[outlier_df_train.distance < 0.68].filename_outlier.tolist()
outlier_df_test = fd_test.outliers()
list_of_outliers_test = outlier_df_test[outlier_df_test.distance < 0.68].filename_outlier.tolist()
outlier_df_valid = fd_valid.outliers()
list_of_outliers_valid = outlier_df_valid[outlier_df_valid.distance < 0.68].filename_outlier.tolist()Darkish, Vivid, and Blurry Pictures

Step 6: Take away Duplicates, Outliers, and Blurry Pictures
After visualizing the stories and verifying the photographs, we are able to save the duplicate, blurry, darkish, vivid or outlier pictures to a listing to organize for removing. We’ll use delete_images operate to take away the checklist of pictures we found. On this occasion, I solely take away the outlier, blurry and duplicate pictures.
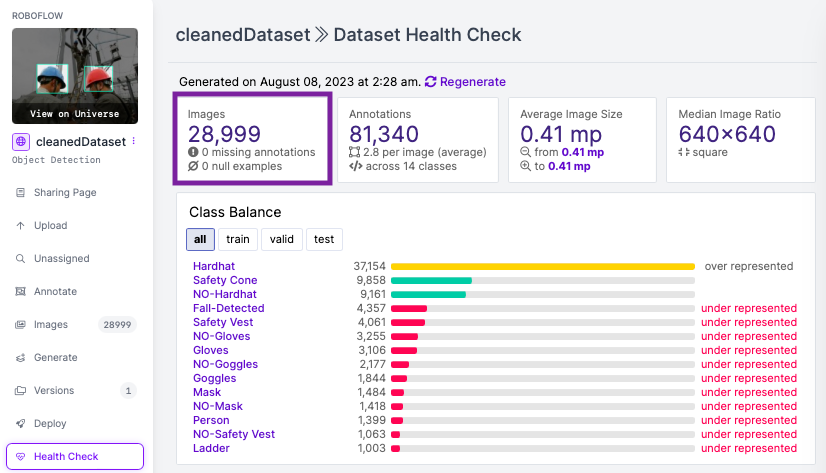
def delete_images(checklist, dir_path): num_deleted = Zero for file_path in checklist: strive: os.take away(file_path) num_deleted += 1 besides Exception as e: print(f"Error occurred when deleting file {file_path}: {e}") print(f"Deleted {num_deleted} pictures") # Depend the variety of pictures left remaining_images = len(os.listdir(dir_path)) print(f"There are {remaining_images} pictures left within the listing {dir_path}.")With this method, we decreased our dataset by ~26% from 39,542 to 28,999 pictures, sustaining a constant mannequin efficiency (mAP50) of 0.79 to XX. This system is a sensible methodology to preserve computational assets and time whereas preserving the range of our knowledge and never considerably impacting mannequin efficiency.
By cleansing your dataset upfront of labeling, you’ll be able to considerably cut back price and time in the course of the labeling course of.
Step 7: Practice and Re-deploy
After you have completely cleaned and optimized your dataset, you’ll be able to add it again to Roboflow. This ensures streamlined integration of your refined knowledge. After profitable importing, you’ll be able to seamlessly start the coaching course of to achieve the very best mannequin efficiency.
You should use your cleaned dataset straight utilizing the code snippet and prepare utilizing YOLOv8.
challenge = rf.workspace("roboflow-ngkro").challenge("cleaneddataset")
dataset = challenge.model(1).obtain("yolov8")mannequin = YOLO('yolov8n.pt')
mannequin.prepare(knowledge=dataset.location + '/knowledge.yaml', epochs=100, imgsz=640)After cleansing the dataset, we retrained the mannequin and noticed the next:
Unique dataset mAP: 0.79

Cleaned dataset mAP: 0.765

The outcomes present that the cleaned knowledge led to related efficiency with ~26% much less knowledge whereas saving us a major coaching time and computation price. This emphasizes the significance of high quality knowledge administration.
Deploy Your Mannequin
After attaining a performant mannequin on the cleaned dataset, the deployment part is a vital step. That is the place the educated mannequin is transitioned from a theoretical assemble to a sensible answer, able to be examined.
Shifting ahead, you’ll be able to deploy fashions with precision throughout numerous cloud and edge environments.
path_to_trained_weight = "./runs/detect/prepare"
challenge.model(1).deploy("yolov8", path_to_trained_weight)Conclusion
On this tutorial, we demonstrated how one can optimize a pc imaginative and prescient mannequin by cleansing the dataset and eradicating duplicate, extremely related, or outlier pictures. By making use of these strategies, we’re in a position to preserve the range of our knowledge whereas lowering its measurement, finally saving computational assets and time with out considerably sacrificing mannequin efficiency.



