In recent times, each pc imaginative and prescient and AI have centered on the attract of huge, general-purpose multimodal fashions resembling OpenAI’s GPT-Four with Imaginative and prescient or Google’s Gemini. Nevertheless, current experiments spotlight how domain-specific fashions, like a specialised particular person or automobile detection model, usually outperform bigger general-purpose fashions from Google Cloud and AWS of their respective use instances in pace and efficiency.
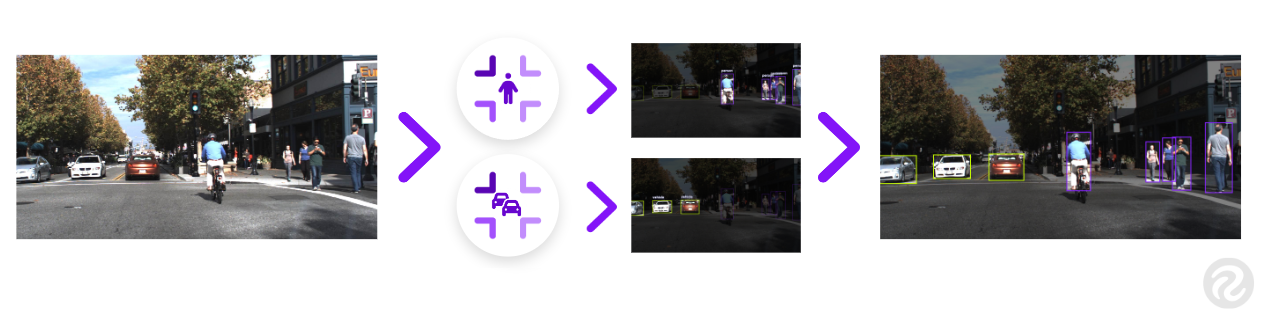
On this information, we are going to discover learn how to benefit from the experience of two (or extra) domain-specific fashions to label knowledge and prepare a brand new mannequin. Then, we are going to consider the brand new mixed mannequin to see the way it compares to a number of domain-specific specialised fashions, in addition to bigger fashions like COCO and black-box choices from Google Cloud Imaginative and prescient and AWS Rekognition.
Why Label with A number of Fashions?
There are situations by which the advantages of mixing a mannequin, with the flexibility of a bigger mannequin whereas sustaining the accuracy and pace of a domain-specific mannequin, will be useful.
- Prepare a mannequin with out accumulating knowledge: If you wish to shortly bootstrap a mannequin, you possibly can mix numerous datasets and use a number of fashions to make constant annotations throughout datasets
- Add an object on an present mannequin: In situations the place you need to add a brand new class to your mannequin, you possibly can shortly use your present mannequin, in addition to a mannequin specialised to the extra object, to complement your present mannequin.
- Eradicate the necessity to run a number of particular fashions concurrently: If you have already got a number of specialised fashions for a similar use, mix them for operational effectivity and pace.
For our instance, we are going to label a dataset of photos for a self-driving automotive that had some lacking labels. To shortly get an preliminary model educated, we are able to routinely label this dataset utilizing a particular person detection mannequin and a automobile detection mannequin.
Step 1: Create or Obtain a Dataset
As a way to use the specialised fashions to coach a mixed mannequin to your use case, it’s good to acquire or add photos to your dataset. It’s also possible to seek for photos on Roboflow Universe to shortly get began on constructing out your mannequin.
For our instance, we will likely be utilizing a subset of photos from the Udacity Autonomous Driving dataset on Roboflow Universe.
Step 2: Use Autodistill for Annotation
Normally, at this level, we might begin labeling our photos. Fortunately, we now have two specialised fashions we are able to use to shortly label our photos utilizing Autodistill. First, we configure Autodistill to label utilizing our Universe fashions.
from autodistill_roboflow_universe import RoboflowUniverseModel
from autodistill.detection import CaptionOntology model_configs = [ ("vehicle-detection-3mmwj", 1), {"people-detection-o4rdr", 7}
] base_model = RoboflowUniverseModel( ontology=CaptionOntology( { "particular person": "particular person", "automobile": "automobile" }
), api_key="YOUR_ROBOFLOW_API_KEY", model_configs=model_configs,
)Then, utilizing a characteristic in Autodistill and Google Colab, we are able to run fashions towards our photos and have them sync immediately throughout the Roboflow interface.
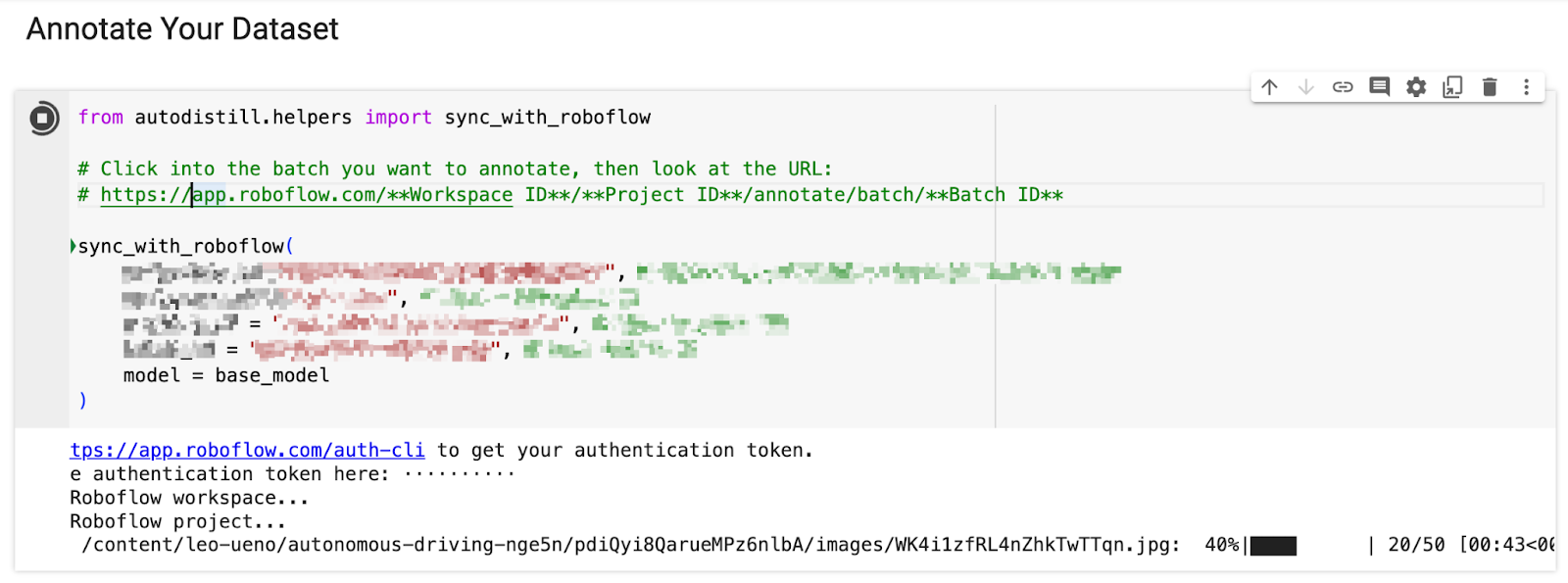
As soon as we kick off labeling, it took simply a few minutes to label over 150 photos. As soon as the dataset is labeled, we are able to evaluation it for accuracy and proper errors earlier than including it to our dataset.
🗒️
Whereas it principally labored effectively, when labeling a bigger dataset, it may be helpful to run labeling jobs in smaller batches and modify overlap and confidence values as wanted.
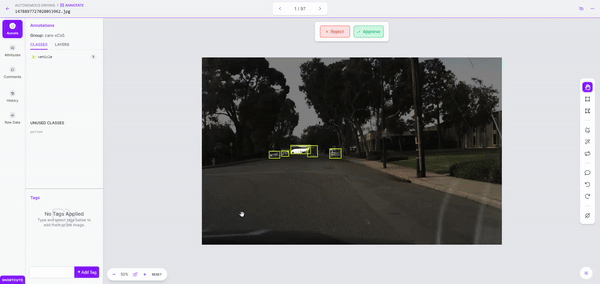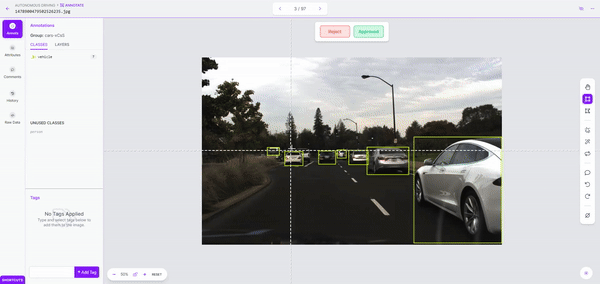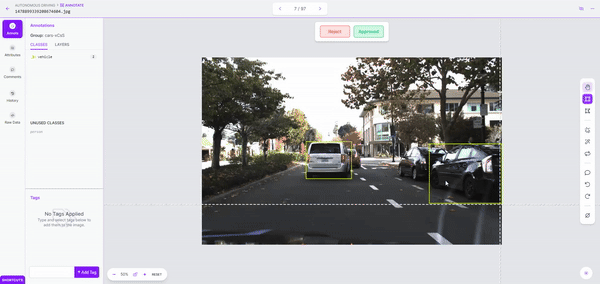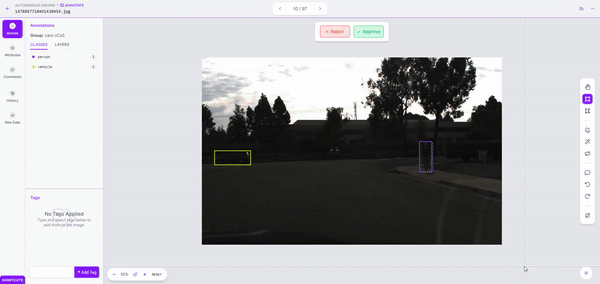
Step 3: Mannequin Coaching
As soon as we now have our photos labeled, we are able to transfer on to coaching the primary model of our mannequin, reaching an accuracy of 83.4%.

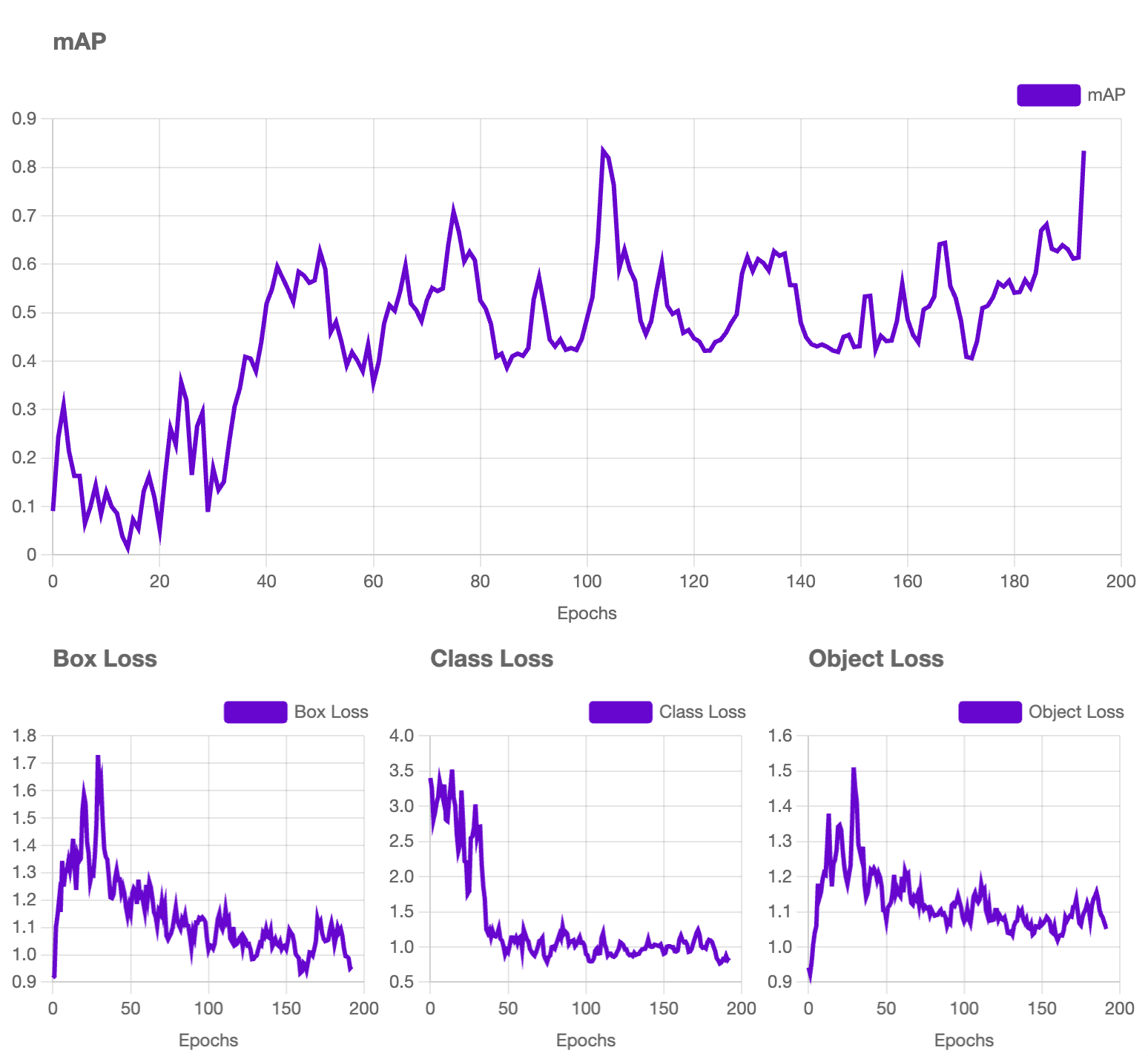
Evaluating the Mixed Mannequin
Now that we now have our mannequin educated, we are able to run some evaluations to see if the explanations for combining the fashions maintain true.
First, we are going to consider the mixed mannequin towards two of the specialised fashions we used. Then we are going to see how the mannequin performs towards different choices like COCO, Google Cloud Imaginative and prescient, and Amazon Rekognition.
Specialised Fashions
To see how our new mannequin performs, we are able to run predictions on the take a look at splits of the specialised mannequin datasets utilizing the hosted inference API.
In our outcomes, we see a small (5~10 milliseconds) hit on our inference time.
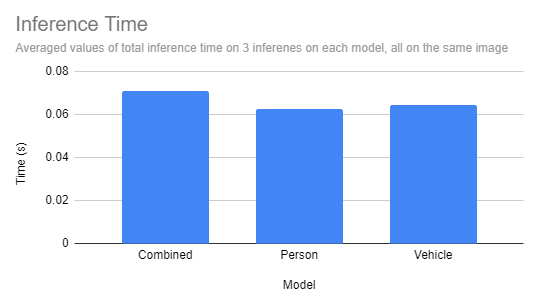
Different Massive Imaginative and prescient Fashions
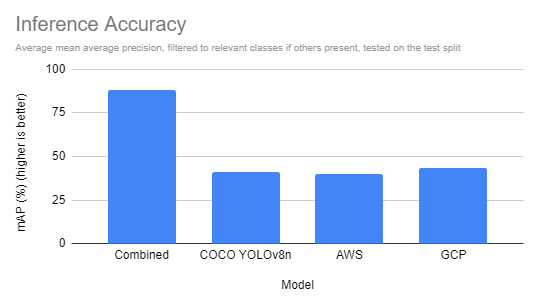
Whereas having a comparable inference time to different specialised fashions is helpful, the detections we’re performing can usually be executed with massive imaginative and prescient fashions. Together with evaluating two cloud choices from Google Cloud Imaginative and prescient and Amazon’s AWS Rekognition, we are able to additionally examine our “Quick” mixed mannequin educated on Roboflow towards a equally sized YOLOv8n Microsoft COCO mannequin.
When it comes to accuracy, the mixed mannequin, educated on photos from our dataset and annotated by our domain-specific fashions, outperformed all different choices by a substantial margin, which is to be anticipated of a mannequin educated on comparable photos for a similar use case.
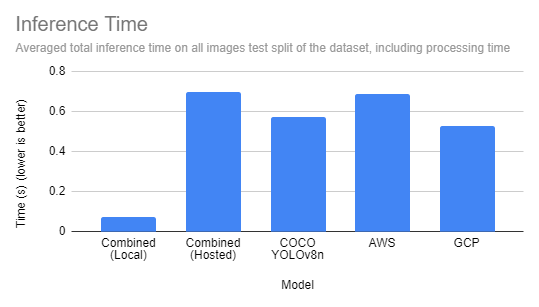
Moreover, a mixed mannequin, bigger than a specialised mannequin but smaller than the opposite massive fashions, offers a possibility to host the mannequin regionally, utilizing our open-source Inference package deal. Operating fashions regionally offers a drastic pace benefit, whereas a managed hosted inference API offers comparable speeds to different big-box fashions.
Conclusion
On this information, we laid out use instances for why utilizing domain-specific fashions for brand new mannequin coaching will be helpful, walked by way of the steps for coaching your personal mixed mannequin, after which evaluated our mannequin to show the usefulness of mixing the experience of two specialised imaginative and prescient fashions on a customized dataset.
We noticed that it not solely carried out equally to the specialised fashions we used to create our mannequin, but it surely outperformed different choices in accuracy and pace.



