Machine studying includes understanding the connection between unbiased and dependent variables. When engaged on machine studying tasks, a substantial period of time is devoted to duties like Exploratory Knowledge Evaluation and have engineering. One other essential side of mannequin growth is hyperparameter tuning.
Hyperparameter tuning focuses on fine-tuning the hyperparameters to allow the machine to assemble a strong mannequin that performs nicely on unseen knowledge. Efficient hyperparameter tuning, along with high quality characteristic engineering, can considerably improve the efficiency of the mannequin. Whereas many superior machine studying fashions like Bagging (Random Forests) and Boosting (XGBoost, LightGBM, and so on.) are already optimized with default hyperparameters, there are cases the place handbook tuning can result in higher mannequin outcomes.
On this weblog put up, we’ll discover some generally used strategies for hyperparameter tuning, together with handbook hyperparameter tuning, grid search, random search, and Bayesian optimization.
Parameters vs Hyperparameters
Understanding the excellence between parameters and hyperparameters is essential in machine studying. Let’s delve into the important thing variations between these two ideas.
What’s a Parameter in Machine Studying?
Parameters in machine studying fashions are the variables that the mannequin learns from the accessible knowledge in the course of the coaching course of. They instantly have an effect on the mannequin’s efficiency and signify the interior state or traits of the mannequin. Parameters are usually optimized by adjusting their values via an optimization algorithm like gradient descent.
For instance, in a linear regression mannequin, the parameters are the coefficients related to every enter characteristic. The mannequin learns these coefficients primarily based on the supplied knowledge, aiming to search out the most effective values that reduce the distinction between the expected output and the precise output.
In Convolutional Neural Networks (CNNs), the parameters include the weights and biases related to the community’s layers. Throughout coaching, these parameters are iteratively adjusted utilizing backpropagation and optimization algorithms akin to stochastic gradient descent.
In brief, parameters are inside to the mannequin and are discovered from the info throughout coaching.
What’s a Hyperparameter?
Hyperparameters outline the configuration or settings of the mannequin. They aren’t discovered from the info, however as an alternative we offer them as inputs earlier than coaching the mannequin. Hyperparameters information the educational course of and influence how the mannequin behaves throughout coaching and prediction.
Hyperparameters are set by machine studying engineer(s) and/or researcher(s) engaged on a mission primarily based on their experience and area data. Tuning these hyperparameters is crucial for enhancing the mannequin’s efficiency and generalization potential.
Examples of hyperparameters in pc imaginative and prescient embody the educational charge, batch dimension, variety of layers, filter sizes, pooling methods, dropout charges, and activation features. These hyperparameters are set primarily based on particular traits of the dataset, the complexity of the duty, and the accessible computational sources.
Fantastic-tuning hyperparameters can have a major influence on the mannequin’s efficiency in pc imaginative and prescient duties. For instance, adjusting the educational charge can have an effect on the convergence velocity and forestall the mannequin from getting caught in suboptimal options. Equally, tuning the variety of layers and filter sizes in a CNN can decide the mannequin’s potential to seize intricate visible patterns and options.
The desk beneath summarizes the distinction between mannequin parameters and hyperparameters.

Frequent Hyperparameters in Laptop Imaginative and prescient
In pc imaginative and prescient duties, varied hyperparameters considerably influence the efficiency and habits of machine studying fashions. Understanding and appropriately tuning these hyperparameters can vastly improve the accuracy and effectiveness of pc imaginative and prescient purposes. Listed below are some frequent hyperparameters encountered in pc imaginative and prescient:
- Studying Fee: The educational charge determines the step dimension at which the mannequin updates its parameters throughout coaching. It influences the convergence velocity and stability of the coaching course of. Discovering an optimum studying charge is essential to forestall underfitting or overfitting.
- Batch Measurement: The batch dimension determines the variety of samples processed in every iteration throughout mannequin coaching. It impacts the coaching dynamics, reminiscence necessities, and generalization potential of the mannequin. Selecting an acceptable batch dimension relies on the accessible computational sources and traits of the dataset on which the mannequin will likely be educated.
- Community Structure: The community structure defines the construction and connectivity of neural community layers. It consists of the variety of layers, the kind of layers (convolutional, pooling, absolutely linked, and so on.), and their configuration. Deciding on an acceptable community structure relies on the complexity of the duty and the accessible computational sources.
- Kernel Measurement: In convolutional neural networks (CNNs), the kernel dimension determines the receptive area dimension used for characteristic extraction. It impacts the extent of element and spatial info captured by the mannequin. Tuning the kernel dimension is crucial to steadiness native and international characteristic illustration.
- Dropout Fee: Dropout is a regularization approach that randomly drops a fraction of the neural community items throughout coaching. The dropout charge determines the chance of “dropping” every unit. Dropout charge helps forestall overfitting by encouraging the mannequin to study extra sturdy options and reduces the dependence on particular items.
- Activation Features: Activation features introduce non-linearity to the mannequin and decide the output of a neural community node. Frequent activation features embody ReLU (Rectified Linear Unit), sigmoid, and tanh. Selecting an acceptable activation operate can influence the mannequin’s capability to seize complicated relationships and its coaching stability.
- Knowledge Augmentation: Knowledge augmentation methods, akin to rotation, scaling, and flipping, improve the variety and variability of the coaching dataset. Hyperparameters associated to knowledge augmentation, akin to rotation angle vary, scaling issue vary, and flipping chance, affect the augmentation course of and may enhance the mannequin’s potential to generalize to unseen knowledge.
- Optimization Algorithm: The selection of optimization algorithm influences the mannequin’s convergence velocity and stability throughout coaching. Frequent optimization algorithms embody stochastic gradient descent (SGD), ADAM, and RMSprop. Hyperparameters associated to the optimization algorithm, akin to momentum, studying charge decay, and weight decay, can considerably influence the coaching course of.
Tuning these hyperparameters requires cautious experimentation and evaluation to search out the optimum values for a selected pc imaginative and prescient activity. The trade-offs between computational sources, dataset traits, and mannequin efficiency should be taken under consideration to realize the most effective outcomes.
The best way to Tune Hyperparameters
On this part, we’ll focus on frequent strategies for tuning hyperparameters in machine studying. Let’s start!
Handbook Hyperparameter Tuning
Handbook hyperparameter tuning is a technique of adjusting the hyperparameters of a machine studying mannequin via handbook experimentation. It includes iteratively modifying the hyperparameters and evaluating the mannequin’s efficiency till passable outcomes are achieved. Though this generally is a time-consuming course of, handbook tuning offers the flexibleness to discover varied hyperparameter mixtures and adapt them to particular datasets and duties.
For instance, let’s take into account a help vector machine (SVM) mannequin. A few of the hyperparameters that may be manually tuned embody the selection of the kernel (linear, polynomial, radial foundation operate), the regularization parameter (C), and the kernel-specific parameters (such because the diploma for a polynomial kernel or gamma for an RBF kernel). By experimenting with completely different values for these hyperparameters and evaluating the mannequin’s efficiency utilizing acceptable metrics, the optimum mixture that yields the most effective outcomes for the precise downside could be decided.
Hyperparameter Tuning with Grid Search
Grid search includes exhaustively looking out a predefined set of hyperparameter values to search out the mixture that yields the most effective efficiency. A grid search systematically explores the hyperparameter house by making a grid or a Cartesian product of all potential hyperparameter values and evaluating the mannequin for every mixture.
In grid search, it’s required to outline the vary of values for every hyperparameter that must be tuned. The grid search algorithm then trains and evaluates the mannequin utilizing all potential mixtures of those values. The efficiency metric, akin to accuracy or imply squared error, is used to find out the most effective set of hyperparameters.
For instance, take into account a Random Forest classifier. The hyperparameters that may be tuned utilizing grid search embody the variety of bushes within the forest, the utmost depth of every tree, and the minimal variety of samples required to separate a node. By defining a grid of values for every hyperparameter, akin to [100, 200, 300] for the variety of bushes and [5, 10, 15] for the utmost depth, grid search explores all potential mixtures (e.g., 100 bushes with a most depth of 5, 200 bushes with a most depth of 10, and so on.). The mannequin is educated and evaluated for every mixture, and the best-performing set of hyperparameters is chosen.
Hyperparameter Tuning with Random Search
Not like grid search, which exhaustively evaluates all potential mixtures, random search randomly samples from a predefined distribution of hyperparameter values. This sampling course of permits for extra environment friendly and scalable exploration of the hyperparameter house.
In grid search, it’s required to outline the vary of values for every hyperparameter that must be tuned. In distinction, utilizing a random search the distribution or vary of values is outlined for every hyperparameter that must be tuned. The random search algorithm then samples mixtures of hyperparameter values from these distributions and evaluates the mannequin’s efficiency. By iteratively sampling and evaluating a specified variety of mixtures, random search goals to establish the hyperparameter settings that yield the most effective efficiency.
For instance, take into account a gradient boosting machine (GBM) mannequin. The hyperparameters that may be tuned utilizing random search embody the educational charge, the utmost depth of the bushes, and the subsampling ratio.
As a substitute of specifying a grid of values, random search permits the engineer to outline chance distributions for every hyperparameter. As an example, a uniform distribution for the educational charge between 0.01 and 0.1, a discrete distribution for the utmost depth between three and 10, and a standard distribution for the subsampling ratio centered round 0.8. The random search algorithm then randomly samples mixtures of hyperparameters and evaluates the mannequin’s efficiency for every mixture.
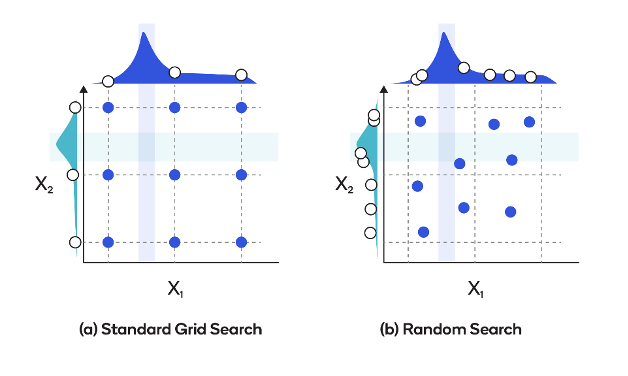
Hyperparameter Tuning with Bayesian Optimization
Bayesian optimization makes use of probabilistic fashions to effectively seek for the optimum hyperparameters. This works by sequentially evaluating a restricted variety of configurations primarily based on their anticipated utility.
In Bayesian optimization, a probabilistic mannequin, akin to a Gaussian course of, is constructed to approximate the target operate’s habits. This mannequin is up to date as new configurations are evaluated, capturing the relationships between hyperparameters and the corresponding efficiency. The mannequin is then used to information the search course of and choose the following set of hyperparameters to guage, aiming to maximise the target operate.
For instance, take into account a deep neural community mannequin. Bayesian optimization could be employed to tune hyperparameters akin to the educational charge, dropout charge, and variety of hidden layers. The preliminary configurations are sampled randomly. Because the surrogate mannequin is up to date, the algorithm intelligently selects new configurations to guage primarily based on the anticipated enchancment in efficiency. This iterative course of permits Bayesian optimization to effectively discover the hyperparameter house and establish the settings that yield the most effective mannequin efficiency.
Hyperparameter Tuning with Bayesian Optimization in Laptop Imaginative and prescient
Bayesian optimization is especially useful in hyperparameter tuning for pc imaginative and prescient duties. Listed below are a couple of examples of Bayesian optimization in pc imaginative and prescient:
- Picture Model Switch with Neural Networks: In picture model switch utilizing neural networks, Bayesian optimization could be utilized to tune hyperparameters such because the content material weight, model weight, and the variety of iterations. The mannequin captures the connection between hyperparameters and metrics like perceptual loss and elegance loss. Bayesian optimization guides the search course of to establish hyperparameter settings that end in visually interesting stylized pictures.
- Picture Recognition with Convolutional Neural Networks: Bayesian optimization can be utilized to tune hyperparameters for picture recognition duties utilizing CNNs. Hyperparameters akin to the educational charge, weight decay, and batch dimension could be optimized utilizing this strategy. The mannequin captures the efficiency of the mannequin when it comes to accuracy, and Bayesian optimization intelligently explores the hyperparameter house to establish the mixture that maximizes the popularity efficiency.
- Picture Technology with Variational Autoencoders (VAEs): Bayesian optimization could be employed to tune hyperparameters in picture technology duties utilizing VAEs. Hyperparameters such because the latent house dimension, studying charge, and batch dimension could be optimized. The mannequin captures the reconstruction loss and technology high quality, which can be utilized with Bayesian optimization to establish the hyperparameter settings that result in better-quality generated pictures.
By leveraging probabilistic fashions and clever exploration, Bayesian optimization gives an efficient strategy for hyperparameter tuning in pc imaginative and prescient. It permits for environment friendly navigation of the hyperparameter house and helps establish optimum hyperparameter configurations, resulting in improved efficiency and higher outcomes in varied pc imaginative and prescient duties.
Conclusion
Hyperparameter tuning is an important step in growing correct and sturdy machine studying fashions. Handbook tuning, grid search, random search, and Bayesian optimization are fashionable methods for exploring the hyperparameter house.
Every methodology gives its personal benefits and concerns. Machine studying practitioners work to search out optimum configurations for a given mannequin. Selecting the suitable approach relies on elements akin to search house dimension and computational sources.
Within the area of pc imaginative and prescient, these methods play a significant function in enhancing efficiency and reaching higher outcomes.
By successfully using these methods, practitioners can optimize their fashions and unlock the total potential of their pc imaginative and prescient purposes.



