On this information, we’re going to present you tips on how to label knowledge for, prepare, and deploy a pc imaginative and prescient mannequin in a single command utilizing the brand new autodistill command line interface. Autodistill makes use of basis fashions to label photos to be used in coaching fashions. We are going to prepare a small mannequin that may determine milk bottles on a conveyor belt.
Right here is an instance of our mannequin engaged on a picture in our dataset:

With out additional ado, let’s get began!
What’s Autodistill?
Autodistill is an open supply utility that allows you to use basis imaginative and prescient fashions to coach smaller, task-specific fashions. Autodistill accepts photos and prompts. Most often, prompts are textual content inputs that point out what you determine, and are mapped to a selected label (i.e. “milk bottle” often is the immediate, and “bottle” is the label that’s saved). Autodistill will then use a basis mannequin to label all the photographs in your dataset with the offered prompts.
Massive, basis imaginative and prescient fashions are taking part in a rising position in laptop imaginative and prescient. These fashions have an enormous vary of data about plenty of completely different subjects, however require plenty of reminiscence to run in distinction to fine-tuned, task-specific fashions. The compute necessities make basis fashions impractical to make use of on the sting. Basis fashions are additionally costly and time consuming to tune to a selected use case.
With a basis mannequin akin to CLIP, Grounding DINO, or Phase Something (SAM) used with Grounding DINO, you may robotically label customized knowledge to be used in coaching a imaginative and prescient mannequin. Since all the knowledge that you’ll embrace in your dataset, you’ll have all the data you’ll want to tune, debug, and enhance your mannequin over time.
Autodistill helps a variety of fashions. For instance, you should utilize Grounding DINO for object detection labeling, SAM for segmentation, CLIP, DINOv2, and BLIP for classification, and extra. You’ll be able to then use your labeled knowledge to coach a mannequin with an structure related to the duty kind with which you might be working (i.e. YOLOv5 or YOLOv8 for detection or segmentation, or ViT for classification).
Supported basis fashions can determine a variety of objects, from containers to trash to folks to ladders. They don’t seem to be appropriate for each use case, nonetheless: for brand-specific objects, basis fashions won’t carry out effectively; for unusual objects (i.e. defects), basis fashions will doubtless not be capable of assist as a lot.
For extra background info on Autodistill, try our Autodistlil introductory information, wherein we walked by means of an instance of a mannequin that identifies bottles of milk in a manufacturing facility that produces milk.
Under, we’ll use Autodistill to coach a milk bottle detection mannequin, however in a single command.
The best way to Label Knowledge, Practice, and Deploy a Imaginative and prescient Mannequin in One Command
With the autodistill command line interface and Roboflow, you may label knowledge for, prepare, and deploy a imaginative and prescient mannequin in a single command. Let’s stroll by means of an instance!
Step #1: Set up Autodistill
First, you will want to put in Autodistill. You are able to do so utilizing the next command:
pip set up autodistillAutodistill can be accessible as a single command: `autodistill`. We’ll use this command in just a few moments. However earlier than we will prepare a mannequin, we’d like photos on which to coach our mannequin.
Step #2: Acquire Picture Knowledge
The premise of a effectively performing imaginative and prescient mannequin is a dataset consultant of the objects you wish to determine. If you happen to don’t have photos but, Roboflow may help. Roboflow gives a variety of instruments you should utilize for accumulating picture knowledge. For instance, you should utilize Roboflow Acquire to intelligently acquire knowledge on the sting. Acquire is beneficial if you’ll want to collect knowledge in a particular surroundings.
For this information, we’ll use Roboflow Universe for gathering knowledge. Universe is a neighborhood that shares imaginative and prescient datasets and fashions. There are greater than 200,000 public datasets accessible on Universe. You need to use the semantic search function on Universe to search out datasets related to your use case.
We are going to use a milk bottle detection mannequin. We’ve created a model known as “unannotated” for this instance (model 1). This incorporates solely the uncooked photos with out augmentations.
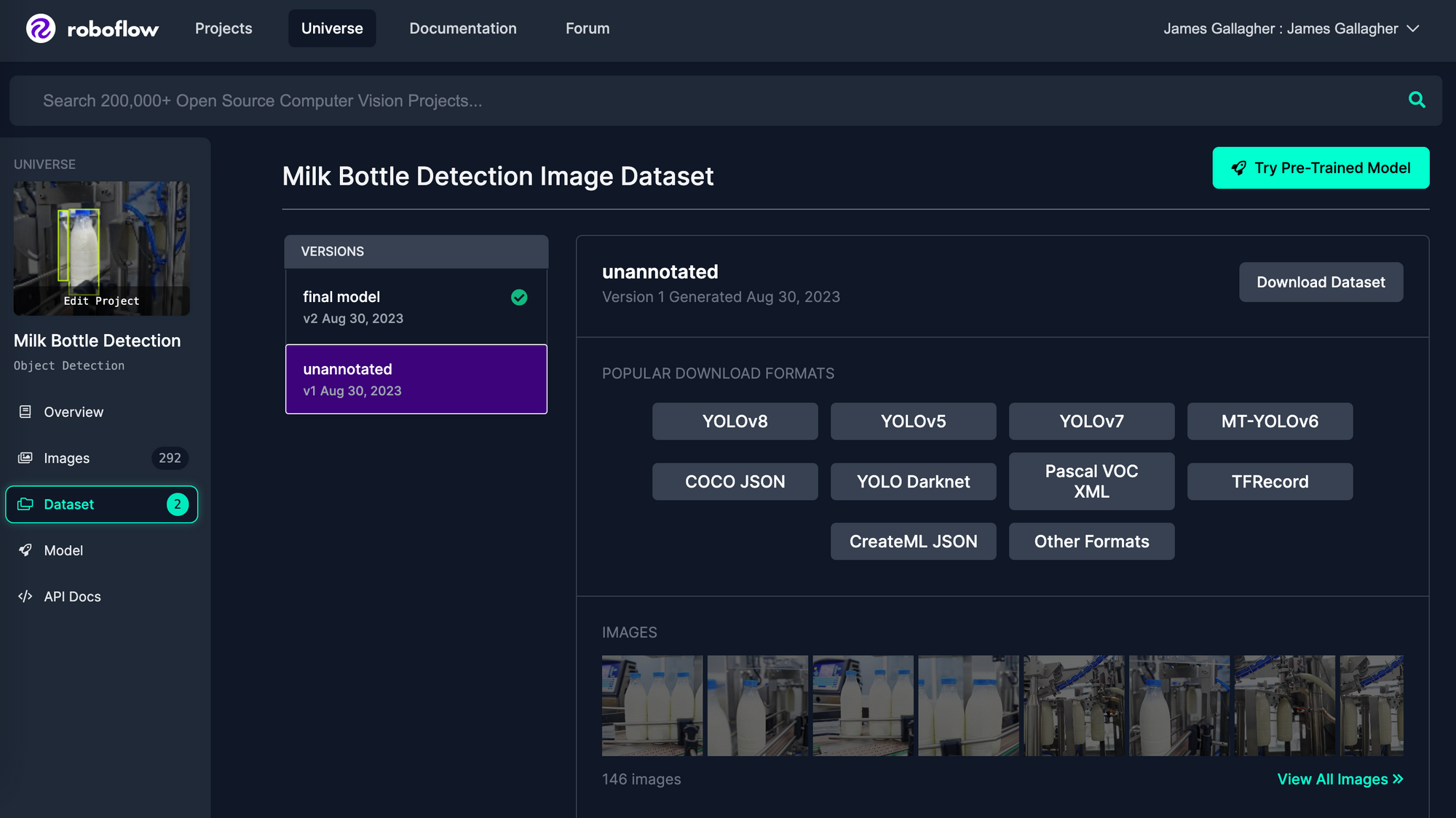
Seek for a dataset related to your use case. When you’ve discovered one, join or check in to your Roboflow account then click on the “Obtain this dataset” button to export the dataset. Export the dataset as a YOLOv8 PyTorch TXT dataset. When requested, specify that you just wish to obtain the dataset as a ZIP file. When the file has downloaded, unzip the file.
We can be utilizing the photographs within the prepare/photos listing, which is the place the coaching photos are within the ZIP export downloaded from Roboflow.
Right here is an instance picture in our milk bottle detection dataset:

Step #3: Create and Consider an Ontology
Subsequent, we have to outline an ontology. An ontology converts what you wish to discover in a picture (the “immediate” given to a basis mannequin) to a label that can be saved in your closing dataset. You’ll be able to determine many various kinds of objects in a picture utilizing a single ontology.
For this instance, we’re labeling packages. We are going to use the next ontology as a place to begin:
{ "milk bottle": "bottle", "blue cap": "cap" }On this ontology, we map the immediate “milk bottle” to the label “bottle”, and “blue cap” to “cap”. Let’s see how this ontology performs on a picture.
Run the next command, and substitute out the picture path with a picture on which you wish to check an ontology:
autodistill testing --ontology='{ "milk bottle": "bottle", "blue cap": "cap" }' --test=TrueThis command will run the ontology on a single picture and present the outcomes:

Our mannequin was in a position to efficiently determine each bottles (in purple containers) and a bottle cap (within the inexperienced field).
We are able to consider our immediate on a number of photos at a time, too.
Copy as much as 4 photos consultant of your dataset into a brand new folder known as “testing”. We suggest doing this for consistency throughout analysis. Then, run the next command:
autodistill testing --ontology='{ "milk bottle": "bottle", "blue cap": "cap" }' --test=TrueThe place your ontology is a JSON string just like the one we outlined earlier.
While you run this command, the bottom mannequin will label as much as 4 photos within the offered folder and show the outcomes, one after the other. You need to use this to check an ontology to visually consider how the ontology performs. When a picture pops up, you may shut it to view the subsequent one, till all 4 photos have been displayed.
Our ontology carried out effectively with our photos, figuring out milk bottles (purple containers) and bottle caps (inexperienced containers). In case your ontology doesn’t carry out effectively, attempt a unique immediate (“milk bottle” and “blue cap” within the above instance).
By default, Grounding DINO is chosen because the mannequin to be used with labeling. You’ll be able to outline a unique mannequin utilizing the –base_model flag. You’ll find an inventory of supported fashions, together with the duty sorts for which you should utilize the fashions, by operating autodistill fashions.
For example, you can use the next command to auto-label photos for a classification mannequin utilizing CLIP. This command will label an object both “milk bottle” or “one thing else:
autodistill testing –-ontology='{ "milk bottle": "bottle", "one thing else": "one thing else" }' --task_type="classification" --base="clip"Step #4: Run Autodistill
To run Autodistill, we have to determine on:
- Photographs (which we’ve)
- A base mannequin
- A goal mannequin
The bottom mannequin is the mannequin we’ll use to label photos. The goal mannequin is the kind of mannequin that can be skilled. For this information, we’ll use Grounding DINO as our base mannequin, because it performs effectively on object detection duties, and YOLOv8 for our goal mannequin.
As soon as our mannequin has been skilled, we’ll add it to Roboflow for deployment. To take action, create a free Roboflow account and retrieve your API key. By deploying your mannequin on Roboflow, you get entry to a scalable API by means of which you’ll be able to run inference, in addition to SDKs you should utilize to run inference on a variety of gadgets (i.e. within the browser and on iOS).
Now we’re able to run Autodistill. Run the next command under, substituting the requisite values:
autodistill photos --base-model="grounding_dino" --target-model="yolov8" --ontology '{"immediate": "label"}' --output-folder ./datasetIf you’d like your challenge to be personal, set --project_license to “personal”. That is solely accessible for purchasers on a starter or enterprise plan.
While you run the command above, your photos can be labeled, then a mannequin can be skilled. This mannequin can be uploaded to Roboflow to be used in operating inference. An interactive progress bar will seem displaying the standing of labeling, then the mannequin coaching course of will kick off.
The period of time it takes for the Autodistill command to run will depend upon the variety of photos in your dataset, what base and goal fashions you might be utilizing, in addition to the {hardware} on which you might be operating Autodistill.
The weights out of your skilled mannequin will all the time be saved in your native machine so you should utilize them as you want.
Step #5: Use Your Educated Mannequin on Roboflow
As soon as your mannequin has been skilled and uploaded to Roboflow, you might be prepared to check your mannequin! We are able to accomplish that within the interactive Roboflow net interface. Go to the Roboflow dashboard, open the brand new mannequin you’ve created with the identify you specified within the Autodistill command. Click on on “Deploy” within the sidebar to open up an interactive widget in which you’ll be able to check your mannequin.
Right here is an instance of our mannequin engaged on a picture from our check set:

Our mannequin efficiently recognized bottles and bottle caps! The mannequin confidence is kind of low, however the confidence would doubtless improve if we had been to coach for greater than the 25 epochs over which this mannequin was skilled. You’ll be able to check out the mannequin on Roboflow Universe.
Conclusion
Autodistill lets you, in a single command, label knowledge for, prepare, and deploy laptop imaginative and prescient fashions. Basis fashions like Grounding DINO, SAM, and CLIP can be utilized for robotically labeling photos in your dataset. Autodistill will then use your labeled photos to coach a goal mannequin (i.e. YOLOv8).
You need to use Autodistill for an enormous vary of use instances. With that mentioned, there are limitations: basis fashions can not determine each object. Above, we outlined an strategy for testing inference on a picture. This can be utilized for each testing completely different ontologies and evaluating whether or not Autodistill may help along with your use case.
Now you’ve the information you’ll want to prepare a imaginative and prescient mannequin with out labeling photos utilizing Autodistill.



