Masks R-CNN, quick for Masks Area-based Convolutional Neural Community, is an extension of the Quicker R-CNN object detection algorithm used for each object detection and occasion segmentation duties in laptop imaginative and prescient.
The numerous adjustments launched by Masks R-CNN from Quicker R-CNN are:
- Changing ROIPool with ROIAlign to deal with the issue of misalignments between the enter characteristic map;
- The area of curiosity (ROI) pooling grid, and;
- Using Function Pyramid Community (FPN) that enhances the capabilities of Masks R-CNN by offering a multi-scale characteristic illustration, enabling environment friendly characteristic reuse, and dealing with scale variations in objects.
What units Masks R-CNN aside is its potential to not solely detect objects inside a picture but in addition to exactly phase and establish the pixel-wise boundaries of every object. This fine-grained segmentation functionality is achieved by way of the addition of an additional “masks head” department to the Quicker R-CNN mannequin.
On this weblog put up, we are going to take an in-depth have a look at Masks R-CNN works, the place the mannequin performs nicely, and what limitations exist with the mannequin.
With out additional ado, let’s start!
What’s Masks R-CNN?
Masks R-CNN is a deep studying mannequin that mixes object detection and occasion segmentation. It’s an extension of the Quicker R-CNN structure.
The important thing innovation of Masks R-CNN lies in its potential to carry out pixel-wise occasion segmentation alongside object detection. That is achieved by way of the addition of an additional “masks head” department, which generates exact segmentation masks for every detected object. This permits fine-grained pixel-level boundaries for correct and detailed occasion segmentation.
Two vital enhancements built-in into Masks R-CNN are ROIAlign and Function Pyramid Community (FPN). ROIAlign addresses the restrictions of the normal ROI pooling technique through the use of bilinear interpolation throughout the pooling course of. This mitigates misalignment points and ensures correct spatial data seize from the enter characteristic map, resulting in improved segmentation accuracy, significantly for small objects.
FPN performs a pivotal position in characteristic extraction by setting up a multi-scale characteristic pyramid. This pyramid incorporates options from completely different scales, permitting the mannequin to achieve a extra complete understanding of object context and facilitating higher object detection and segmentation throughout a variety of object sizes.

Masks R-CNN Structure
The structure of Masks R-CNN is constructed upon the Quicker R-CNN structure, with the addition of an additional “masks head” department for pixel-wise segmentation. The general structure may be divided into a number of key elements:
Spine Community
The spine community in Masks R-CNN is usually a pre-trained convolutional neural community, reminiscent of ResNet or ResNeXt. This spine processes the enter picture and extracts high-level options. An FPN is then added on prime of this spine community to create a characteristic pyramid.
FPNs are designed to deal with the problem of dealing with objects of various sizes and scales in a picture. The FPN structure creates a multi-scale characteristic pyramid by combining options from completely different ranges of the spine community. This pyramid consists of options with various spatial resolutions, from high-resolution options with wealthy semantic data to low-resolution options with extra exact spatial particulars.

The FPN in Masks R-CNN consists of the next steps:
- Function Extraction: The spine community extracts high-level options from the enter picture.
- Function Fusion: FPN creates connections between completely different ranges of the spine community to create a top-down pathway. This top-down pathway combines high-level semantic data with lower-level characteristic maps, permitting the mannequin to reuse options at completely different scales.
- Function Pyramid: The fusion course of generates a multi-scale characteristic pyramid, the place every degree of the pyramid corresponds to completely different resolutions of options. The highest degree of the pyramid incorporates the highest-resolution options, whereas the underside degree incorporates the lowest-resolution options.
The characteristic pyramid generated by FPN permits Masks R-CNN to deal with objects of assorted sizes successfully. This multi-scale illustration permits the mannequin to seize contextual data and precisely detect objects at completely different scales throughout the picture.
Area Proposal Community (RPN)
The RPN is accountable for producing area proposals or candidate bounding packing containers which may include objects throughout the picture. It operates on the characteristic map produced by the spine community and proposes potential areas of curiosity.
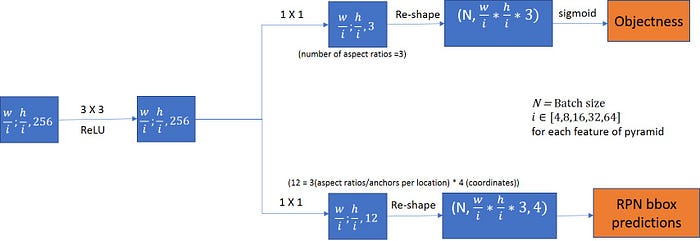
ROIAlign
After the RPN generates area proposals, the ROIAlign (Area of Curiosity Align) layer is launched. This step helps to beat the misalignment concern in ROI pooling.
ROIAlign performs a vital position in precisely extracting options from the enter characteristic map for every area proposal, guaranteeing exact pixel-wise segmentation in occasion segmentation duties.
The first function of ROIAlign is to align the options inside a area of curiosity (ROI) with the spatial grid of the output characteristic map. This alignment is essential to stop data loss that may happen when quantizing the ROI’s spatial coordinates to the closest integer (as accomplished in ROI pooling).
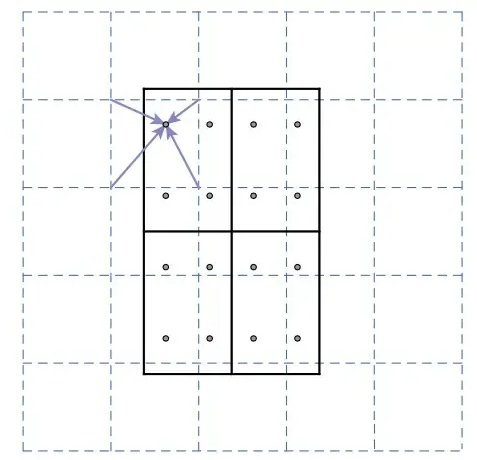
The ROIAlign course of entails the next steps:
- Enter Function Map: The method begins with the enter characteristic map, which is usually obtained from the spine community. This characteristic map incorporates high-level semantic details about the complete picture.
- Area Proposals: The Area Proposal Community (RPN) generates area proposals (candidate bounding packing containers) which may include objects of curiosity throughout the picture.
- Dividing into Grids: Every area proposal is split into a hard and fast variety of equal-sized spatial bins or grids. These grids are used to extract options from the enter characteristic map akin to the area of curiosity.
- Bilinear Interpolation: In contrast to ROI pooling, which quantizes the spatial coordinates of the grids to the closest integer, ROIAlign makes use of bilinear interpolation to calculate the pooling contributions for every grid. This interpolation ensures a extra exact alignment of the options throughout the ROI.
- Output Options: The options obtained from the enter characteristic map, aligned with every grid within the output characteristic map, are used because the consultant options for every area proposal. These aligned options seize fine-grained spatial data, which is essential for correct segmentation.
Through the use of bilinear interpolation throughout the pooling course of, ROIAlign considerably improves the accuracy of characteristic extraction for every area proposal, mitigating misalignment points.
This exact alignment permits Masks R-CNN to generate extra correct segmentation masks, particularly for small objects or areas that require effective particulars to be preserved. In consequence, ROIAlign contributes to the sturdy efficiency of Masks R-CNN in occasion segmentation duties.
Masks Head
The Masks Head is an extra department in Masks R-CNN, accountable for producing segmentation masks for every area proposal. The pinnacle makes use of the aligned options obtained by way of ROIAlign to foretell a binary masks for every object, delineating the pixel-wise boundaries of the situations. The Masks Head is usually composed of a number of convolutional layers adopted by upsample layers (deconvolution or transposed convolution layers).

Throughout coaching, the mannequin is collectively optimized utilizing a mix of classification loss, bounding field regression loss, and masks segmentation loss. This permits the mannequin to be taught to concurrently detect objects, refine their bounding packing containers, and produce exact segmentation masks.
Masks R-CNN Efficiency
Within the desk under we present the occasion segmentation Masks R-CNN efficiency and a few visible outcomes on COCO check dataset.
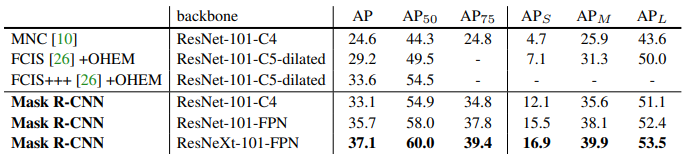
The COCO 2015 and 2016 segmentation challenges have been gained by the MNC and FCIS fashions, respectively. Surprisingly, Masks R-CNN achieved higher outcomes than the extra intricate FCIS+++, which contains multi-scale coaching/testing, horizontal flip testing, and OHEM. It is noteworthy that each one the entries signify outcomes from particular person fashions.

Masks R-CNN Limitations
Masks R-CNN excels in a number of areas, making it a robust mannequin for varied laptop imaginative and prescient duties reminiscent of object detection, occasion segmentation, multi-object segmentation, and complicated scene dealing with.
Nonetheless, Masks R-CNN has some limitations to think about:
- Computational Complexity: Coaching and inference may be computationally intensive, requiring substantial assets, particularly for high-resolution photographs or massive datasets.
- Small-Object Segmentation: Masks R-CNN might battle to precisely phase very small objects because of restricted pixel data.
- Knowledge Necessities: Coaching Masks R-CNN successfully requires a considerable amount of annotated knowledge, which may be time-consuming and costly to amass.
- Restricted Generalization to Unseen Categories: The mannequin’s potential to generalize to unseen object classes is proscribed, particularly when knowledge is scarce.
Conclusion
Masks R-CNN merges object detection and occasion segmentation, offering the aptitude to not solely detect objects but in addition to exactly delineate their boundaries on the pixel degree. Through the use of a Function Pyramid Community (FPN) and the Area of Curiosity Align (ROIAlign), Masks R-CNN achieves sturdy efficiency and accuracy.
Masks R-CNN does have sure limitations, reminiscent of its computational complexity and reminiscence utilization throughout coaching and inference. It could encounter challenges in precisely segmenting very small objects or dealing with closely occluded scenes. Buying a considerable quantity of annotated coaching knowledge can be demanding, and fine-tuning the mannequin for particular domains might require cautious parameter tuning.



