Amazon Rekognition, a set of pc imaginative and prescient APIs by Amazon Internet Companies, has a variety of visible evaluation options, comparable to facial recognition, content material moderation, occupancy detection, OCR and emblem detection. Underlying a number of of those options, Amazon Rekognition Picture has a basic object detection API, which detects 289 doable courses of objects from folks to marriage ceremony robes.
On this information, we’ll present methods to consider the effectiveness of a {custom} use-case-specific mannequin to the generic mannequin by Amazon Rekognition. You need to use these steps to guage how your mannequin compares to the AWS endpoint.
Step 1: Discovering an analysis dataset
For this instance, we’ll say that we wish to detect vehicles and we would like a mannequin that may carry out effectively at detecting automobiles in all kinds of situations. To discover a good dataset, we are able to search Roboflow Universe for a educated object detection mannequin.

On this case, to guage how the fashions will carry out in a wide range of settings we’ll use a big, generalized, various dataset like COCO. For this instance, we’ll use a Universe dataset of a subset of COCO restricted to automobiles.
Non-compulsory: Create your personal mannequin or analysis dataset
When you’ve got your personal use case that you just want to examine towards Amazon Rekognition, you may create your personal dataset and prepare a mannequin, then examine that custom-trained mannequin towards how Amazon Rekognition performs.
For instance, you could possibly seize round 100 photos or movies from the place you’d wish to deploy your mannequin after which add the photographs to Roboflow.
You could possibly shortly annotate them and even have Autodistill label the photographs for you.
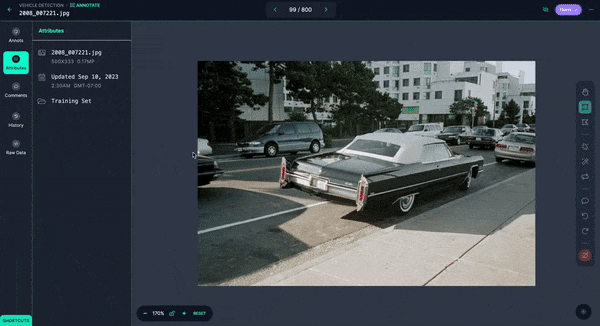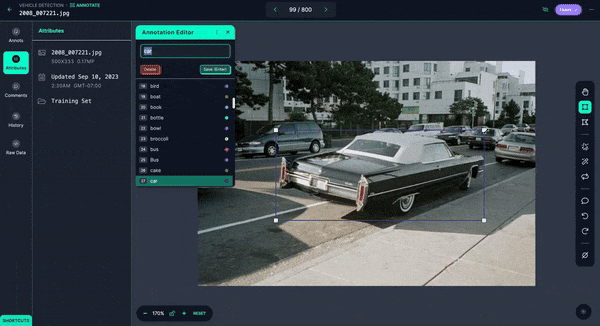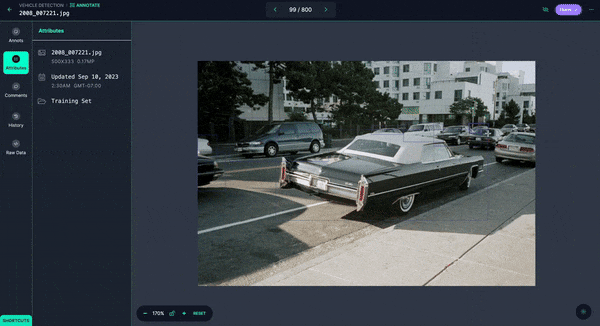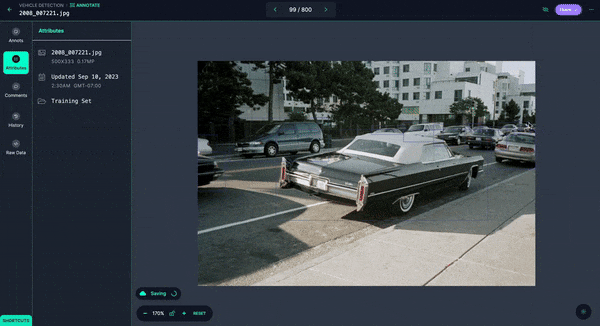
Upon getting your photos annotated, you may add and modify preprocessing and augmentations, then generate a model.

After making a model, you may prepare your mannequin with one click on.
Then, proceed by means of this information the identical manner, however exchange the mannequin with your personal to obtain your challenge.
Step 2: Consider mannequin efficiency
Now that now we have the dataset to guage each fashions towards, we are able to start the analysis course of. We are able to take a look at the fashions and produce the mAP (imply common precision) for each fashions utilizing supervision’s mAP benchmark characteristic.
First, we’ll set up the `roboflow` and `supervision` packages, in addition to `boto3` and `aws-shell`, that are AWS instruments, required to make use of Rekognition on Python.
!pip set up boto3 aws-shell roboflow supervision -qAmazon’s Rekognition mannequin will be accessed by signing up for an AWS account when you don’t have already got one. Then, create an IAM entry key to make use of the API.
Within the pocket book, begin the authentication course of through the use of the CLI command `aws configure` and observe the prompts that seem.
Obtain the Analysis Dataset
Now, we’ll obtain our analysis dataset and use the `DetectionDataset.from_coco()` technique to get it into supervision.
from roboflow import Roboflow
rf = Roboflow(api_key="**YOUR API KEY HERE**")
challenge = rf.workspace("vehicle-mscoco").challenge("vehicles-coco")
dataset = challenge.model(2).obtain("coco")To do that by yourself or with your personal dataset, click on on the Obtain this Dataset button on any object detection dataset on Universe and export in COCO format.

Testing the Rekognition Mannequin
Earlier than we are able to take a look at, we must arrange our class maps. The Rekognition object detection mannequin has 289 courses, lots of which will be overlapping. For our functions, we discovered three courses within the listing of courses that have been related to car detection: `Car` and `Automobile`. In our restricted testing, we discovered that these embody many of the mannequin’s most correct detections, however there could possibly be some cases the place the category `Hearth Truck` is detected, however `Automobile` or `Car` isn’t. We noticed conduct just like this after we examined with folks detection, as we’ll cowl later.
Then, we arrange a callback perform in order that supervision can run the mannequin towards the photographs in our analysis dataset.
As soon as now we have this setup, we are able to begin to consider the efficiency of Rekognition through the use of the mAP benchmark perform, getting a results of 59.05%.
mean_average_precision = sv.MeanAveragePrecision.benchmark( dataset = sv_dataset, callback = callback
)
print(f"Last mAP: {mean_average_precision.map50}")
Testing the Roboflow Universe Mannequin
Now that now we have the outcomes from the Rekognition mannequin, we are able to run the identical analysis with our specialised mannequin from Roboflow Universe.
Coming into the Roboflow API key, we are able to load within the mannequin from Universe. Just like the method with Rekognition, we are able to additionally arrange a callback perform for testing with Supervision.
def callback(np_image): picture = cv2.cvtColor(np_image, cv2.COLOR_RGB2BGR) consequence = mannequin.predict(picture, confidence=45, overlap=50).json() sv_result = sv.Detections.from_roboflow(consequence) return sv_resultConducting the analysis, we get a results of 65.92%, an enchancment of 6.87% from the Rekognition mannequin.

Individual Detection Comparability
Getting outcomes of 65.92% with Universe and 59.05% in Rekognition, we sought to check different standard use circumstances of pc imaginative and prescient. Having beforehand in contrast Google Cloud Imaginative and prescient’s generic object detection API utilizing an individual detection use-case, we determined to conduct an analysis of Amazon Rekognition towards the earlier outcomes.
Initially, we obtained outcomes from Rekognition that have been as little as 29%. In our restricted expertise, we discovered that Rekognition sometimes struggled with returning bounding field places of some courses, whereas not others. To guage Rekognition towards the opposite choices as pretty as doable, we added the courses `Individual`, `Man`, `Male` and `Feminine` to the category map, getting an improved results of 44.67%.

Conclusion
The outcomes of the testing recommend {that a} specialised educated mannequin for a particular use-case can carry out higher. If detecting a single object reliably is of significance, a specialised mannequin could also be value testing. With that mentioned, we additionally acknowledge the advantage of fashions like AWS Rekognition and Google Cloud Imaginative and prescient in that they’ve the flexibility to detect an especially giant variety of objects. You will need to think about the particular cause and surroundings for a pc imaginative and prescient and select the perfect resolution in your use case accordingly.


