YOLO-World is a real-time, zero-shot object detection mannequin developed by Tencent’s AI Lab. As a result of YOLO-World is a zero-shot mannequin, you’ll be able to present textual content prompts to the mannequin to determine objects of curiosity in a picture with out coaching or fine-tuning a mannequin.

YOLO-World launched a brand new paradigm of object detection: “immediate then detect”. This eliminates the necessity for just-in-time textual content encoding, a property of different zero-shot fashions like Grounding DINO that reduces the potential velocity of the mannequin. In line with the YOLO World paper, the small model of the mannequin achieves as much as 74.1 FPS on a V100 GPU.
On this information, we’re going to present you methods to detect objects utilizing YOLO-World. We’ll use the Roboflow Inference Python bundle, which lets you deploy a variety of pc imaginative and prescient fashions by yourself {hardware}.
With out additional ado, let’s get began!
Detect Objects with YOLO-World
To detect objects with YOLO-World, we are going to:
- Set up the required dependencies
- Import dependencies and obtain instance information
- Run object detection with YOLO-World with Roboflow Inference
- Plot our predictions utilizing supervision
Step #1: Set up Dependencies
We’re going to use Roboflow Inference to run YOLO-World and the Supervision Python bundle to handle predictions from the mannequin. You may set up these dependencies with the next instructions:
pip set up -q inference-gpu[yolo-world]==0.9.12rc1
pip set up -q supervision==0.19.0rc3Step #2: Import Dependencies and Obtain Knowledge
First, we have to import the dependencies we have to use YOLO-World. Create a brand new Python file and add the next code:
import cv2
import supervision as sv from tqdm import tqdm
from inference.fashions.yolo_world.yolo_world import YOLOWorldIn a brand new terminal, run the next instructions to obtain instance information. For this information, we will probably be utilizing an instance of an individual with a canine and, later, a video with candies.
wget -P {HOME} -q https://media.roboflow.com/notebooks/examples/canine.jpegIn your Python file, set variables that hyperlink to this information:
import os
HOME = os.getcwd()
print(HOME) SOURCE_IMAGE_PATH = f"{HOME}/canine.jpeg"With that mentioned, you should use any picture you need on this information.
Step #3: Run the Mannequin
There are three variations of YOLO-World: Small (S), Medium (M), and Giant (L). These variations can be found with the next mannequin IDs:
yolo_world/syolo_world/myolo_world/l
For this information, we are going to use the massive mannequin. Whereas slower, this mannequin will permit us to attain the most effective efficiency on our job.
Subsequent, we have to load our mannequin and set the courses we need to determine. Whereas different zero-shot object detection fashions ask for textual content prompts at inference time, YOLO-World asks you to set your prompts earlier than inference.
Use the next code to load your mannequin, set courses, then run inference:
mannequin = YOLOWorld(model_id="yolo_world/l") courses = ["person", "backpack", "dog", "eye", "nose", "ear", "tongue"]
mannequin.set_classes(courses) picture = cv2.imread(SOURCE_IMAGE_PATH)
outcomes = mannequin.infer(picture)
detections = sv.Detections.from_inference(outcomes)Within the above code snippet, we declare objects we need to determine, ship these courses the mannequin, then run inference on a picture. We load our detections into an sv.Detections object. This object can be utilized with the Supervision Python bundle to govern, visualize, and mix detections.
To visualise your predictions, use the next code:
BOUNDING_BOX_ANNOTATOR = sv.BoundingBoxAnnotator(thickness=2)
LABEL_ANNOTATOR = sv.LabelAnnotator(text_thickness=2, text_scale=1, text_color=sv.Shade.BLACK) annotated_image = picture.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections)
sv.plot_image(annotated_image, (10, 10))On this code, we declare two annotators: one to plot bounding containers, and one other to plot labels. We then visualize the outcomes. Listed below are the outcomes from our mannequin on a picture:

Our mannequin efficiently recognized two courses: individual and canine. The others have been filtered out as a result of the default confidence degree in Inference is about to 0.5 (50%). YOLO-World typically returns low confidences, even when the bounding containers are right.
We will resolve this by lowering the arrogance degree used within the mannequin.infer() operate. Within the code beneath, we set the arrogance to 0.003, then customise our annotator in order that we show the arrogance of every class:
picture = cv2.imread(SOURCE_IMAGE_PATH)
outcomes = mannequin.infer(picture, confidence=0.003)
detections = sv.Detections.from_inference(outcomes) labels = [
f"{classes[class_id]} {confidence:0.3f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
] annotated_image = picture.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections, labels=labels)
sv.plot_image(annotated_image, (10, 10))Listed below are the outcomes:
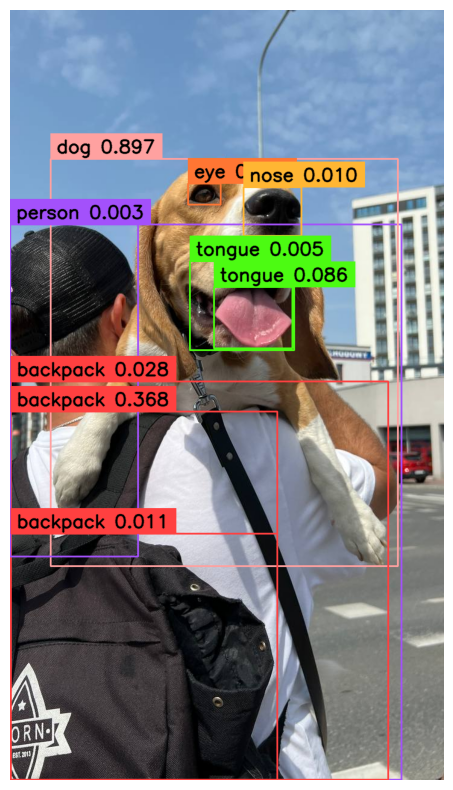
Of notice, there are a number of cases the place bounding containers with the identical class overlap. We will remedy this by making use of Non-Most Suppression (NMS), a way for eradicating duplicate or close-to-duplicate bounding containers.
You may apply NMS by including .with_num(threshold=-0.1) to the top of your .from_inference() information loader, like so:
picture = cv2.imread(SOURCE_IMAGE_PATH)
outcomes = mannequin.infer(picture, confidence=0.003)
detections = sv.Detections.from_inference(outcomes).with_nms(threshold=0.1)Let’s visualize our predictions once more:
labels = [
f"{classes[class_id]} {confidence:0.3f}"
for class_id, confidence
in zip(detections.class_id, detections.confidence)
] annotated_image = picture.copy()
annotated_image = BOUNDING_BOX_ANNOTATOR.annotate(annotated_image, detections)
annotated_image = LABEL_ANNOTATOR.annotate(annotated_image, detections, labels=labels)
sv.plot_image(annotated_image, (10, 10))
Listed below are the outcomes:
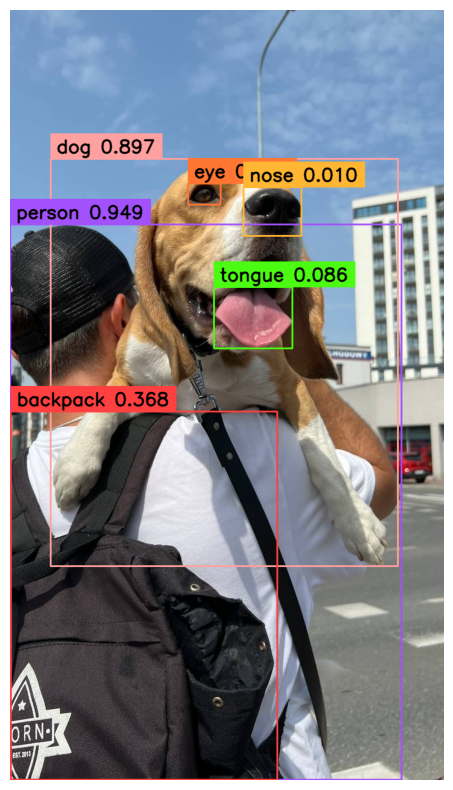
Within the picture above, the duplicate bounding containers on the backpack and tongue courses have been eliminated.
Conclusion
YOLO-World is a zero-shot object detection mannequin developed by Tencent’s AI Lab. You may deploy YOLO-World by yourself {hardware} with Roboflow Inference, pc imaginative and prescient inference software program.
On this information, we walked via methods to detect objects with YOLO-World. We loaded YOLO-World, ran inference on a picture, then displayed outcomes with the supervision Python bundle.
Within the accompanying pocket book, we stroll via the instance above in addition to a bonus instance that exhibits methods to run inference on a video utilizing YOLO-World and supervision.
If you’re enthusiastic about studying extra in regards to the structure behind YOLO World, confer with our “What’s YOLO World?” weblog publish.



