PaliGemma, launched by Google in Could 2024, is a Giant Multimodal Mannequin (LMM). You need to use PaliGemma for Visible Query Answering (VQA), to detect objects on photographs, and even generate segmentation masks.
Whereas PaliGemma has zero-shot capabilities – which means the mannequin can determine objects with out fine-tuning – such talents are restricted. Google strongly recommends fine-tuning the mannequin for optimum efficiency in particular domains.
One area the place foundational fashions sometimes don’t carry out properly is medical imaging. On this information, we’ll stroll by means of fine-tuning PaliGemma to detect fractures in X-ray photographs. To do that, we’ll use one of the datasets accessible on Roboflow Universe.
JAX/FLAX PaliGemma 3B is accessible in three completely different variations, differing in enter picture decision (224, 448, and 896) and enter textual content sequence size (128, 512, and 512 tokens respectively).
To restrict GPU reminiscence consumption and allow fine-tuning in Google Colab, we’ll use the smallest model, paligemma-3b-pt-224, on this tutorial. You have to a GPU runtime with at the least 12GB of obtainable RAM, and Google Colab with an NVIDIA T4 is adequate.
💡
To fine-tune PaliGemma, we’ll:
- Obtain the article detection dataset in PaliGemma JSONL format;
- Set up the required dependencies;
- Obtain pre-trained PaliGemma weights and tokenizer from Kaggle;
- Finetune PaliGemma utilizing JAX;
- Save our mannequin for later use.
💡
With out additional ado, let’s get began!
Step #1: Obtain an object detection dataset
To fine-tune PaliGemma for object detection, you want a dataset within the PaliGemma JSONL format. This format will not be sometimes used for coaching conventional pc imaginative and prescient fashions like YOLO however is often used for coaching language fashions. A dataset in JSONL format has every line as a separate JSON object, like an inventory of particular person data.
In our case, every file incorporates the identify of the related picture, a prefix (immediate) that can be handed to the mannequin, and a suffix (anticipated response) from the mannequin. Here’s a single object from our dataset:
{'picture': 'n_0_2513_png_jpg.rf.1f679ff5dec5332cf06f6b9593c8437b.jpg', 'prefix': 'detect fracture', 'suffix': '<loc0390><loc0241><loc0472><loc0440> fracture'}Within the immediate, take note of the key phrase detect adopted by an inventory of courses we wish to `detect`, separated by semicolons. The anticipated detection result’s described by a bounding field in ‘<loc{Y1}><loc{X1}><loc{Y2}><loc{X2}>’ and the category identify. The values X1, Y1, X2, and Y2 describe the situation of the bounding field, normalized to a picture measurement of 1024×1024. Every worth ought to have Four digits; if a coordinate is shorter, it’s padded with zeros.
Roboflow has full help for the PaliGemma JSONL format, and it may be used to export any of the 250,000+ datasets on Roboflow Universe.
First, set up the required dependencies to obtain and parse a dataset:
pip set up roboflow supervisionFor this information, we’ll obtain a fracture detection dataset utilizing a Roboflow API key:
from google.colab import userdata
from roboflow import Roboflow ROBOFLOW_API_KEY = userdata.get('ROBOFLOW_API_KEY') rf = Roboflow(api_key=ROBOFLOW_API_KEY)
mission = rf.workspace("srinithi-s-tzdkb").mission("fracture-detection-rhud5")
model = mission.model(4)
dataset = model.obtain("PaliGemma")Earlier than we begin fine-tuning, let’s make sure the dataset is appropriately formatted by visualizing one of many examples from our dataset.
from PIL import Picture
import json first = json.hundreds(open(f"{dataset.location}/dataset/_annotations.prepare.jsonl").readline())
print(first) picture = Picture.open(f"{dataset.location}/dataset/{first.get('picture')}")
CLASSES = first.get('prefix').change("detect ", "").break up(" ; ")
detections = from_pali_gemma(first.get('suffix'), picture.measurement, CLASSES) sv.BoundingBoxAnnotator().annotate(picture, detections)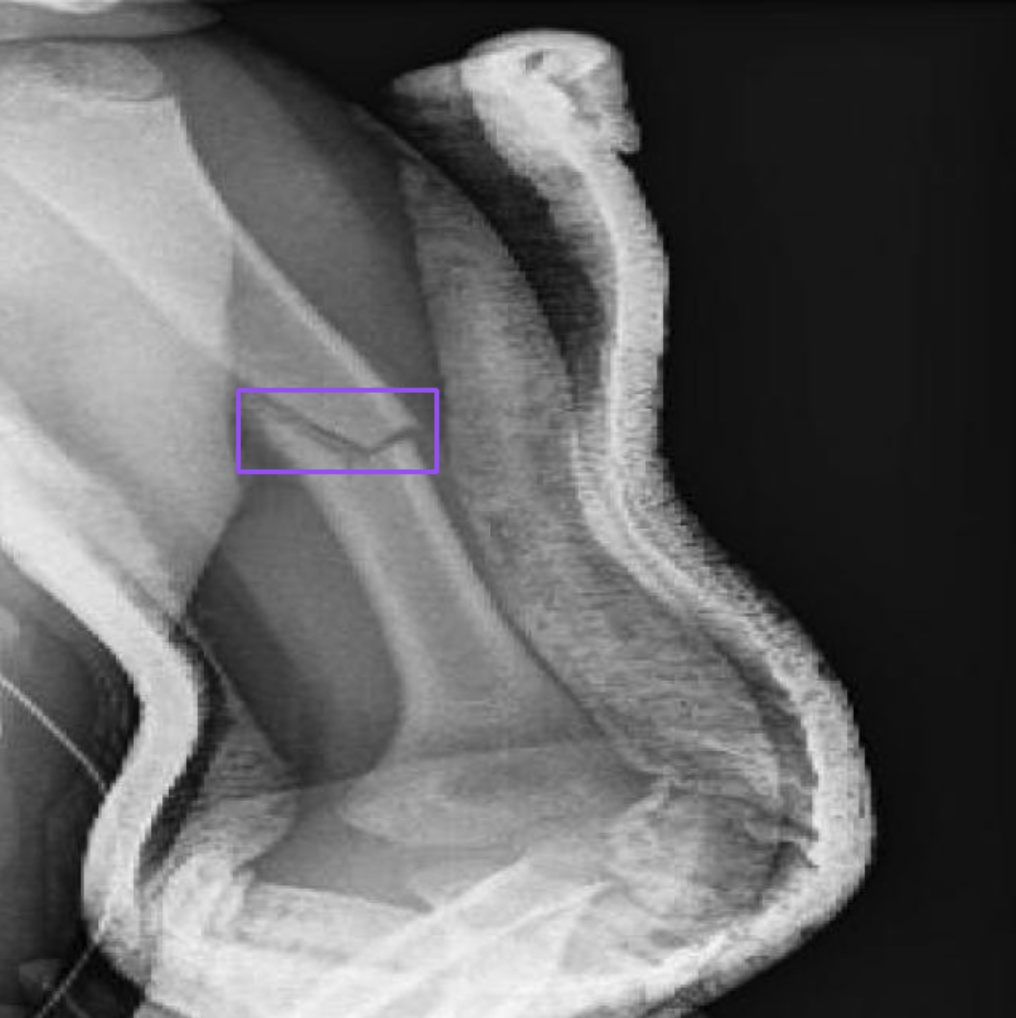
Now that we all know our annotations are appropriately displayed, we will arrange our Python surroundings and begin fine-tuning. A lot of the code on this part comes from the official Google Colab launched by the PaliGemma workforce.
Step #2: Mannequin setup
To coach a PaliGemma mannequin for object detection, we’re going to use the big_vision mission maintained by Google Analysis. We are able to set up this mission utilizing the next code:
import os
import sys # TPUs with
if "COLAB_TPU_ADDR" in os.environ:
increase "It appears you might be utilizing Colab with distant TPUs which isn't supported." # Fetch big_vision repository if python does not learn about it and set up
# dependencies wanted for this pocket book.
if not os.path.exists("big_vision_repo"):
!git clone --quiet --branch=major --depth=1
https://github.com/google-research/big_vision big_vision_repo # Append big_vision code to python import path
if "big_vision_repo" not in sys.path:
sys.path.append("big_vision_repo") # Set up lacking dependencies. Assume jax~=0.4.25 with GPU accessible.
!pip3 set up -q "overrides" "ml_collections" "einops~=0.7" "sentencepiece"After you have put in big_vision, you subsequent must obtain the PaliGemma mannequin weights. These weights can be found on Kaggle. You have to a Kaggle account to obtain the weights. You have to comply with the PaliGemma phrases of service in Kaggle in an effort to use the mannequin weights.
After you have arrange your Kaggle account and agreed to the phrases of service, you may obtain the PaliGemma weights utilizing the next code:
import os
from google.colab import userdata # Observe: `userdata.get` is a Colab API. If you happen to're not utilizing Colab, set the env
# vars as applicable or make your credentials accessible in ~/.kaggle/kaggle.json os.environ["KAGGLE_USERNAME"] = userdata.get('KAGGLE_USERNAME')
os.environ["KAGGLE_KEY"] = userdata.get('KAGGLE_KEY') import os
import kagglehub MODEL_PATH = "./PaliGemma-3b-pt-224.f16.npz"
if not os.path.exists(MODEL_PATH):
print("Downloading the checkpoint from Kaggle, this might take a couple of minutes....")
# Observe: kaggle archive incorporates the identical checkpoint in a number of codecs.
# Obtain solely the float16 mannequin.
MODEL_PATH = kagglehub.model_download('google/PaliGemma/jax/PaliGemma-3b-pt-224', MODEL_PATH)
print(f"Mannequin path: {MODEL_PATH}") TOKENIZER_PATH = "./PaliGemma_tokenizer.mannequin"
if not os.path.exists(TOKENIZER_PATH):
print("Downloading the mannequin tokenizer...")
!gsutil cp gs://big_vision/PaliGemma_tokenizer.mannequin {TOKENIZER_PATH}
print(f"Tokenizer path: {TOKENIZER_PATH}")Step #3: Practice a PaliGemma mannequin for object detection
With the mannequin weights downloaded, we at the moment are prepared to coach a PaliGemma mannequin on a customized object detection dataset. The code for this step is lengthy, so this information is not going to embody the code. Observe the accompanying pocket book for all the code you want to prepare your mannequin.
The steps that we have to comply with to coach a mannequin are:
- Import all the required dependencies
- Assemble the mannequin utilizing the ml_collections library.
- Load the mannequin weights into RAM to be used in coaching.
- Transfer parameters to GPU/TPU reminiscence to be used in coaching.
- Outline preprocessing features for photographs and tokens.
- Outline a coaching loop that can iterate over all the prepare and validation examples, utilizing the PaliGemma jsonl format.
- Run a coaching loop with a specified studying charge and variety of examples to fine-tune the mannequin.
All of those steps are documented within the Colab pocket book that accompanies this submit.
In our Colab, we set the batch measurement to eight, the training charge to 0.01, and outline the variety of prepare and analysis steps as:
BATCH_SIZE = 8
TRAIN_EXAMPLES = 512
LEARNING_RATE = 0.01 TRAIN_STEPS = TRAIN_EXAMPLES // BATCH_SIZE
EVAL_STEPS = TRAIN_STEPS // 8
With a skilled mannequin, we will now take a look at it.
Step #4: Take a look at the fine-tuned object detection mannequin
In our Colab pocket book, we declare a perform referred to as make_predictions which takes in a perform that iterates over photographs and runs inference on every picture.
We are able to use this perform to check our fine-tuned object detection mannequin:
html_out = ""
for picture, caption in make_predictions(validation_data_iterator(), batch_size=4):
html_out += render_example(picture, caption)
show(HTML(html_out))Here’s a collection of outcomes from our mannequin when run on the validation dataset for our mission:
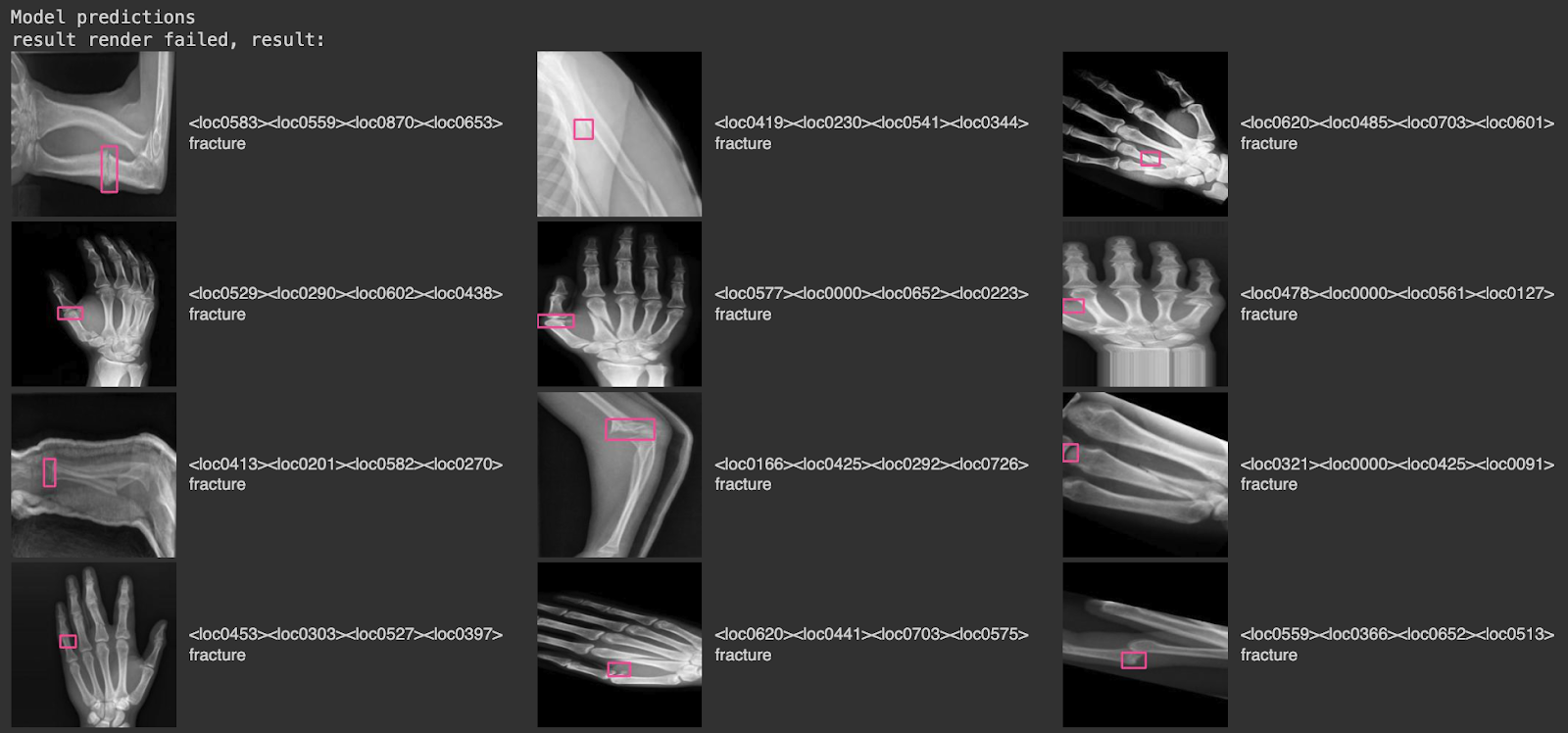
On this picture, there are photographs from the validation set, with pink bounding containers that correspond to detections from the mannequin, and textual content labels on the correct that inform us what class was recognized (“fracture”).
It can save you your mannequin utilizing the next code for later use:
flat, _ = big_vision.utils.tree_flatten_with_names(params)
with open("/content material/fine-tuned-PaliGemma-3b-pt-224.f16.npz", "wb") as f:
np.savez(f, **{okay: v for okay, v in flat})Roboflow is actively engaged on an answer for deploying PaliGemma fashions by yourself {hardware} that can devour the saved weights. We are going to replace this information when our deployment resolution is accessible. For now, you may deploy the default weights utilizing Roboflow Inference.
Conclusion
PaliGemma is a multimodal imaginative and prescient mannequin developed by Google. PaliGemma can be utilized to determine the situation of objects in a picture, and determine segmentation masks that correspond with particular objects in a picture.
On this information, we walked by means of how you can fine-tune PaliGemma for object detection utilizing a customized dataset, close to a pocket book tailored from Google’s official PaliGemma fine-tuning pocket book.
We downloaded a appropriate dataset from Roboflow Universe, visually checked to make sure annotations have been appropriately saved within the PaliGemma format, then ran a coaching job on Google Colab. We then examined our mannequin with the corresponding validation dataset for our mission, reaching robust outcomes.



