PaliGemma is a imaginative and prescient language mannequin (VLM) developed and launched by Google that has multimodal capabilities.
In contrast to different VLMs, equivalent to OpenAI’s GPT-4o, Google Gemini, and Anthropic’s Claude 3 which have struggled with object detection and segmentation, PaliGemma has a variety of skills, paired with the flexibility to fine-tune for higher efficiency on particular duties.
Google’s resolution to launch an open multimodal mannequin with the flexibility to fine-tune on customized information is a significant breakthrough for AI. PaliGemma offers you the chance to create customized multimodal fashions which you’ll self-host within the cloud and doubtlessly on bigger edge units like NVIDIA Jetsons.
What’s PaliGemma?
PaliGemma, launched alongside different merchandise on the 2024 Google I/O occasion, is a mixed multimodal mannequin primarily based on two different fashions from Google analysis: SigLIP, a imaginative and prescient mannequin, and Gemma, a big language mannequin, which suggests the mannequin is a composition of a Transformer decoder and a Imaginative and prescient Transformer picture encoder. It takes each picture and textual content as enter and generates textual content as output, supporting a number of languages.
Essential points of PaliGemma:
Whereas PaliGemma is beneficial with out fine-tuning, Google says it’s “not designed for use straight, however to be transferred (by fine-tuning) to particular duties utilizing the same immediate construction” which suggests no matter baseline we are able to observe with the mannequin weights is simply the tip of the iceberg for a way helpful the mannequin could also be in a given context. PaliGemma is pre-trained on WebLI, CC3M-35L, VQ²A-CC3M-35L/VQG-CC3M-35L, OpenImages, and WIT.
Hyperlinks to PaliGemma Sources
Google provided ample sources to start out prototyping with PaliGemma and we’ve curated the very best high quality info for these of you who need to bounce into utilizing PaliGemma instantly. We recommend getting began with the next sources:
On this put up we are going to discover what PaliGemma can do, examine PaliGemma benchmarks to different LMMs, perceive PaliGemma’s limitations, and see the way it performs in actual world use instances. We’ve put collectively learnings that may prevent time whereas testing PaliGemma.
Let’s get began!
What can PaliGemma do?
PaliGemma is a single-turn imaginative and prescient language mannequin and it really works finest when fine-tuning to a selected use case. This implies you’ll be able to enter a picture and textual content string, equivalent to a immediate to caption the picture, or a query and PaliGemma will output textual content in response to the enter, equivalent to a caption of the picture, a solution to a query, or an inventory of object bounding field coordinates.
Duties PaliGemma is suited to carry out relate to the benchmarking outcomes Google launched throughout the next duties:
- Wonderful-tuning on single duties
- Picture query answering and captioning
- Video query answering and captioning
- Segmentation
This implies PaliGemma is beneficial for simple and particular questions associated to visible information.
We’ve created a desk to point out PaliGemma outcomes relative to different fashions primarily based on reported outcomes on frequent benchmarks.

Whereas benchmarks are useful information factors, they don’t inform your complete story. PaliGemma is constructed to be fine-tuned and the opposite fashions are closed-source. For the needs of exhibiting which choices can be found, we examine in opposition to different, typically a lot bigger, fashions which can be unable to be fine-tuned.
It’s price experimenting to see if fine-tuning with customized information will result in higher efficiency on your particular use case than out-of-the-box efficiency with different fashions.
Later on this put up, we are going to examine PaliGemma to different open supply VLMs and LMMs utilizing an ordinary set of assessments. Proceed studying to see the way it performs.
How you can Wonderful-tune PaliGemma
One of many thrilling points of PaliGemma is its capability to finetune on customized use-case information. A pocket book printed by Google’s PaliGemma workforce showcases find out how to fine-tune on a small dataset.
It’s essential to notice that on this instance, solely the eye layers are fine-tuned and due to this fact the efficiency enhancements could also be restricted.
How you can Deploy and Use PaliGemma
You’ll be able to deploy PaliGemma utilizing an open supply Inference package deal. First, we might want to set up Inference, in addition to another packages wanted to run PaliGemma.
📓
!git clone https://github.com/roboflow/inference.git
%cd inference
!pip set up -e .!pip set up git+https://github.com/huggingface/transformers.git speed up -qSubsequent, we are going to arrange PaliGemma by importing the module from Inference and placing in our Roboflow API key.
import inference
from inference.fashions.paligemma.paligemma import PaliGemma pg = PaliGemma(api_key="YOUR ROBOFLOW API KEY")Final, we are able to enter a take a look at picture as a Pillow picture, pair it with a immediate, and watch for the outcome.
from PIL import Picture picture = Picture.open("/content material/canine.webp") # Change to your picture
immediate = "What number of canines are on this picture?" outcome = pg.predict(picture,immediate)When prompted with this picture, we get the correct reply of `1`.

PaliGemma Analysis for Laptop Imaginative and prescient
Subsequent, we are going to consider how PaliGemma does on varied laptop imaginative and prescient duties that we’ve examined utilizing GPT-4o, Claude 3, Gemini, and different fashions.
Right here, we are going to take a look at a number of completely different use instances together with optical character recognition (OCR), doc OCR, doc understanding, visible query answering (VQA), and object detection.

The next analysis assessments have been run utilizing the official Google Hugging Face Area which you need to use to run your individual assessments as effectively.
PaliGemma for Optical Character Recognition (OCR)
Optical character recognition is a pc imaginative and prescient process to return the seen textual content from a picture in machine-readable textual content format. Whereas its a easy process in idea, it may be a tough process to perform in manufacturing purposes.
Beneath we strive OCR with each the prompts that we’ve seen work with different LMMs, asking it to “Learn the serial quantity. Return the quantity with no extra textual content.” With this immediate, it failed, claiming that it didn’t have the coaching or functionality to reply that query.
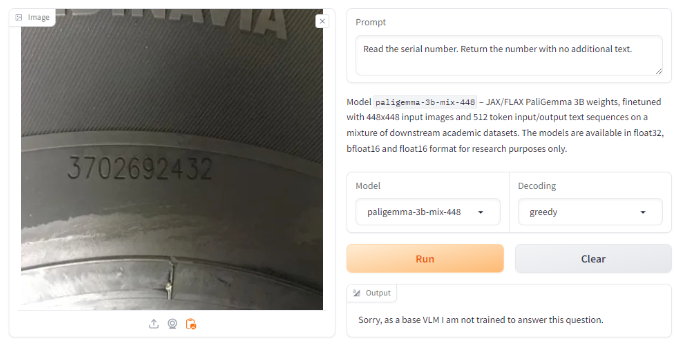
Nonetheless, we all know from the mannequin documentation that it needs to be able to OCR. We tried with the instance immediate supplied within the documentation, `ocr`, the place we obtained a profitable, appropriate outcome.
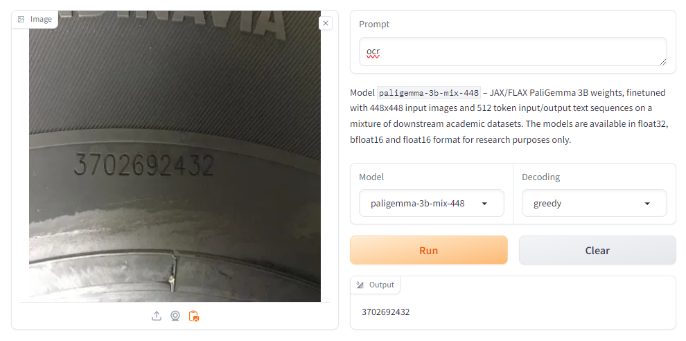
Attempting with a distinct picture with the primary immediate additionally yielded appropriate outcomes, citing a possible limitation of immediate sensitivity.
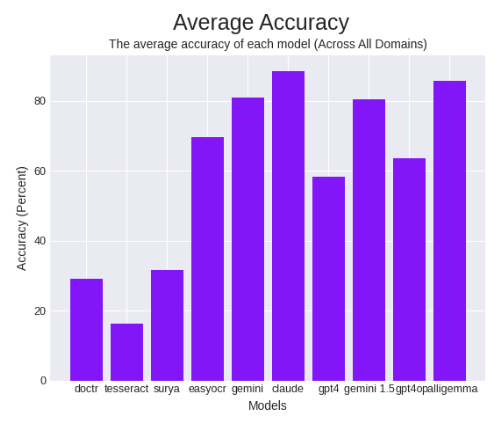
Subsequent, testing on an OCR benchmark that we now have used beforehand to check different OCR fashions like Tesseract, Gemini, Claude, GPT-4o and others, we noticed very spectacular outcomes.
In common accuracy, we noticed 85.84%, beating all different OCR fashions aside from Anthropic’s Claude Three Opus.
PaliGemma additionally achieved comparatively quick speeds. Mixed with the cheaper native nature of the mannequin, PaliGemma appears to be the highest OCR mannequin when it comes to pace effectivity and price effectivity.
🗒️
Velocity effectivity and price effectivity, metrics launched within the OCR benchmarking put up, confer with a metric of accuracy given (divided by) time elapsed and price incurred.
In median pace effectivity, it beats the earlier chief, GPT-4o, set a day earlier when it was launched, by a wholesome margin. When it comes to value effectivity, PaliGemma outperformed the earlier chief, EasyOCR, by virtually thrice, working extra precisely and cheaper.
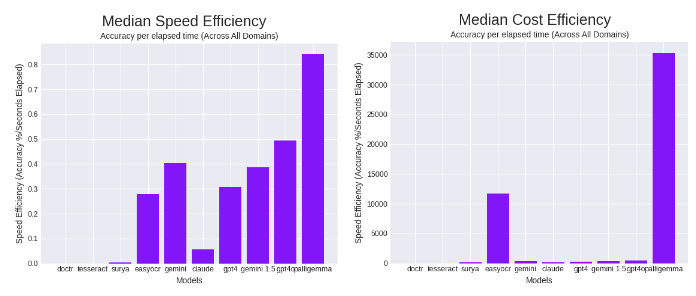
We take into account these outcomes to make PaliGemma a high OCR mannequin given the native and extra light-weight nature of PaliGemma in comparison with the fashions it beat, together with the not too long ago launched GPT-4o, Gemini, and different OCR packages.
Doc Understanding
Doc understanding refers back to the capability to extract related key info from a picture, often with different irrelevant textual content.
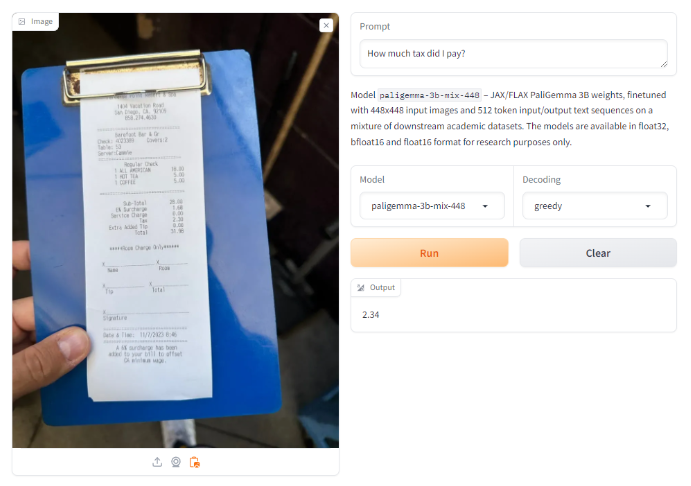
On a picture with a receipt, we ask it to extract the tax paid based on the receipt. Right here, PaliGemma offers a detailed however incorrect outcome persistently throughout a number of makes an attempt.
Nonetheless, on a picture with a pizza menu, when requested to offer the price of a selected pizza, it returned an accurate worth.
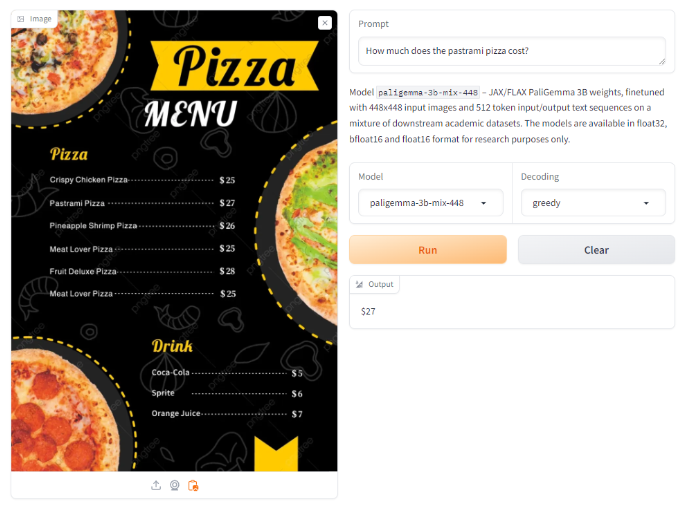
This performs related or equal to the expertise we had with GPT-Four with Imaginative and prescient, the place it failed tax extraction however answered the pizza menu query appropriately. Gemini, Claude Three and the brand new GPT-4o did reply each questions appropriately, in addition to Qwen-VL-Plus, an open supply VLM.
Visible Query Answering (VQA)
Visible Query Answering includes posing a mannequin with a picture and a query requiring some type of recognition, identification, or reasoning.
When posed with a query on how a lot cash was current in an image with Four cash, it answered with Four cash. A technically appropriate reply, however the query requested for the sum of money within the picture.

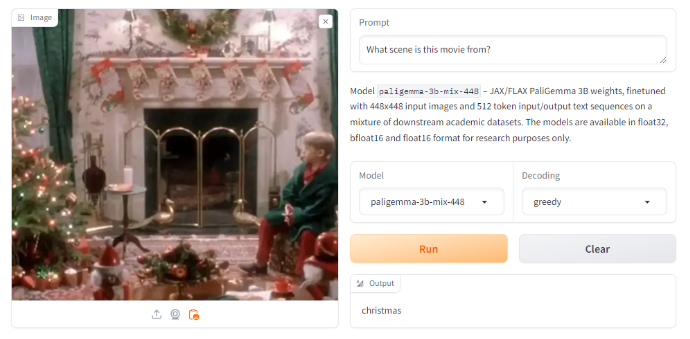
When tasked with figuring out a scene that includes Kevin Mcallister from the film Residence Alone, it responded with “christmas”. We take into account this to be an incorrect reply.
Object Detection
As we talked about earlier, VLMs have historically struggled with object detection, a lot much less occasion segmentation. Nonetheless, PaliGemma is reported to have object detection and occasion segmentation skills.
First, we take a look at with the identical immediate we now have given different fashions previously. Right here, it returns an incorrect, seemingly hallucinated outcome.
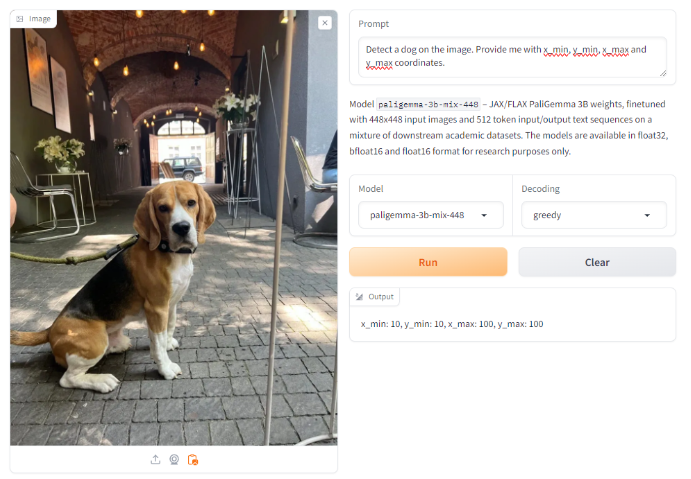
Nonetheless, when prompting with the key phrase `detect`, adopted by the article `canine` (so `detect canine`) as detailed within the mannequin documentation, it appropriately and precisely identifies the canine within the picture. Utilizing the key phrase `phase canine` additionally resulted in an accurate segmentation.

Though it is extremely spectacular {that a} VLM is ready to present object detection and recognition capabilities, it’s price noting that solely fundamental examples, equivalent to these potential with a conventional object detection mannequin, succeeded. When prompted to seek out vehicles, (there’s a automotive current seen by way of the door of the constructing within the again) it returned no outcomes.
Use Circumstances for PaliGemma
Whether or not utilizing PaliGemma zero-shot or fine-tuned on customized information, there are particular use instances tailor-made to PaliGemma’s strengths that may open the door to new AI use instances. Let’s check out a two of them.
Customized Functions
Fashions like Claude 3, Gemini 1.5 Professional, and GPT-4o are used out-of-the-box and utilized to issues they’re suited to unravel. PaliGemmi brings multimodal skills to make use of instances which can be nonetheless unsolved by closed-source fashions as a result of you’ll be able to fine-tune PaliGemma with proprietary information associated to your downside. That is helpful in industries like manufacturing, CPG, healthcare, and safety. When you’ve got a singular downside that closed-models haven’t seen, and can by no means see on account of their proprietary nature, then PaliGemma is a superb entry level into constructing customized AI options.
OCR
As proven earlier on this article, PaliGemma is a powerful OCR mannequin with none extra fine-tuning. When constructing OCR purposes to scale to billions of predictions, latency, value, and accuracy will be tough to stability. Earlier than PaliGemma, closed-source fashions have been the best-in-class choice for efficiency however their value and lack of mannequin possession made them tough to justify in manufacturing. This mannequin can present rapid efficiency and be improved over time by fine-tuning in your particular information.
Limitations of PaliGemma
PaliGemma, and all VLMs, are finest suited to duties with clear directions and should not the perfect instrument for open-ended, advanced, nuanced, or cause primarily based issues. That is the place VLMs are distinct from LMMs and you’ll discover the perfect outcomes when you use the fashions the place they’re most probably to carry out effectively.
When it comes to context, PaliGemma has info primarily based on the pre-training datasets and any information provided throughout fine-tuning. PaliGemma is not going to know info exterior of this and, barring any weights updates with new information from Google or the open supply group, you shouldn’t depend on PaliGemma as a information base.
To get essentially the most out of PaliGemma, and have a cause to make use of the mannequin over different open supply fashions, you’ll need to practice the mannequin on customized information. Its zero-shot efficiency is just not state-of-the-art throughout most benchmarks. Organising a customized coaching pipeline can be essential to warrant utilizing PaliGemma for many use instances.
Lastly, throughout varied assessments, we noticed drastic variations in outcomes with slight modifications to prompts. That is related habits to different LMMs, like YOLO-World, and takes time to grasp find out how to finest immediate the mannequin. Adjustments in a immediate, like eradicating an ‘s’ to make a phrase singular quite than plural, will be the distinction between an ideal detection and an unusable output.
Discover the completely different outcomes primarily based on plural vs singular nouns
Conclusion
Google’s launch of PaliGemma is extremely helpful for the development of multimodal AI. The light-weight open mannequin constructed for fine-tuning means anybody can customized practice their very own giant vision-language mannequin and deploy it for any industrial goal on their very own {hardware} or cloud.
Earlier LMMs have been extraordinarily costly to fine-tune and sometimes require giant quantities of compute to run, making them prohibitive for broad adoption. PaliGemma breaks the mildew and provides individuals constructing customized AI purposes a breakthrough mannequin to create subtle purposes.



