Giant Studying Fashions or LLMs are fairly well-liked phrases when discussing Synthetic intelligence (AI). With the arrival of platforms like ChatGPT, these phrases have now develop into a phrase of mouth for everybody. Immediately, they’re carried out in search engines like google and yahoo and each social media app corresponding to WhatsApp or Instagram. LLMs modified how we work together with the web as discovering related info or performing particular duties was by no means this simple earlier than.
What are Giant Language Fashions (LLMs)?
In generative AI, human language is perceived as a troublesome information sort. If a pc program is skilled on sufficient information such that it will possibly analyze, perceive, and generate responses in pure language and different types of content material, it’s known as a Giant Language Mannequin (LLM). They’re skilled on huge curated coaching information with sizes starting from hundreds to thousands and thousands of gigabytes.
A simple approach to describe LLM is an AI algorithm able to understanding and producing human language. Machine studying particularly Deep Studying is the spine of each LLM. It makes LLM able to deciphering language enter primarily based on the patterns and complexity of characters and phrases in pure language.
LLMs are pre-trained on intensive information on the internet which exhibits outcomes after comprehending complexity, sample, and relation within the language.
Presently, LLMs can comprehend and generate a variety of content material kinds like textual content, speech, photos, and movies, to call just a few. LLMs apply highly effective Pure Language Processing (NLP), machine translation, and Visible Query Answering (VQA).
Some of the frequent examples of an LLM is a digital voice assistant corresponding to Siri or Alexa. Whenever you ask, “What’s the climate at present?”, the assistant will perceive your query and discover out what the climate is like. It then provides a logical reply. This easy interplay between machine and human occurs due to Giant Language Fashions. Because of these fashions, the assistant can learn consumer enter in pure language and reply accordingly.
Emergence and Historical past of LLMs
Synthetic Neural Networks (ANNs) and Rule-based Fashions
The muse of those Computational Linguistics fashions (CL) dates again to the 1940s when Warren McCulloch and Walter Pitts laid the groundwork for AI. This early analysis was not about designing a system however exploring the basics of Synthetic Neural Networks. Nevertheless, the very first language mannequin was a rule-based mannequin developed within the 1950s. These fashions may perceive and produce pure language utilizing predefined guidelines however couldn’t comprehend complicated language or preserve context.
Statistics-based Fashions
After the prominence of statistical fashions, the language fashions developed within the 90s may predict and analyze language patterns. Utilizing possibilities, they’re relevant in speech recognition and machine translation.
Introduction of Phrase Embeddings
The introduction of the phrase embeddings initiated nice progress in LLM and NLP. These fashions created within the Mid-2000s may seize semantic relationships precisely by representing phrases in a steady vector house.
Recurrent Neural Community Language Fashions (RNNLM)
A decade later, Recurrent Neural Community Language Fashions ((RNNLM) have been launched to deal with sequential information. These RNN language fashions have been the primary to maintain context throughout totally different elements of the textual content for a greater understanding of language and output technology.
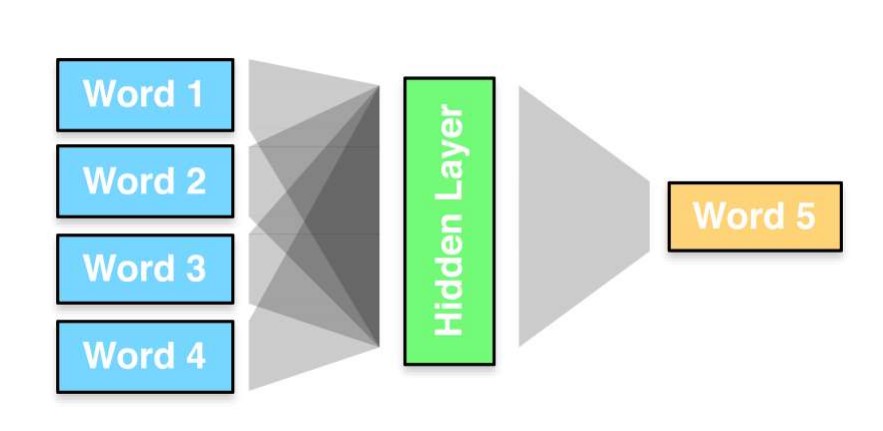
Google Neural Machine Translation (GNMT)
In 2015, Google developed the revolutionary Google Neural Machine Translation (GNMT) for machine translation. The GNMT featured a deep neural community devoted to sentence-level translations slightly than particular person word-base translations with a greater method to unsupervised studying.
It really works on the shared encoder-decoder-based structure with lengthy short-term reminiscence (LSTM) networks to seize context and the technology of precise translations. Large datasets have been used to coach these fashions. Earlier than this mannequin, overlaying some complicated patterns within the language and adapting to doable language buildings was not doable.
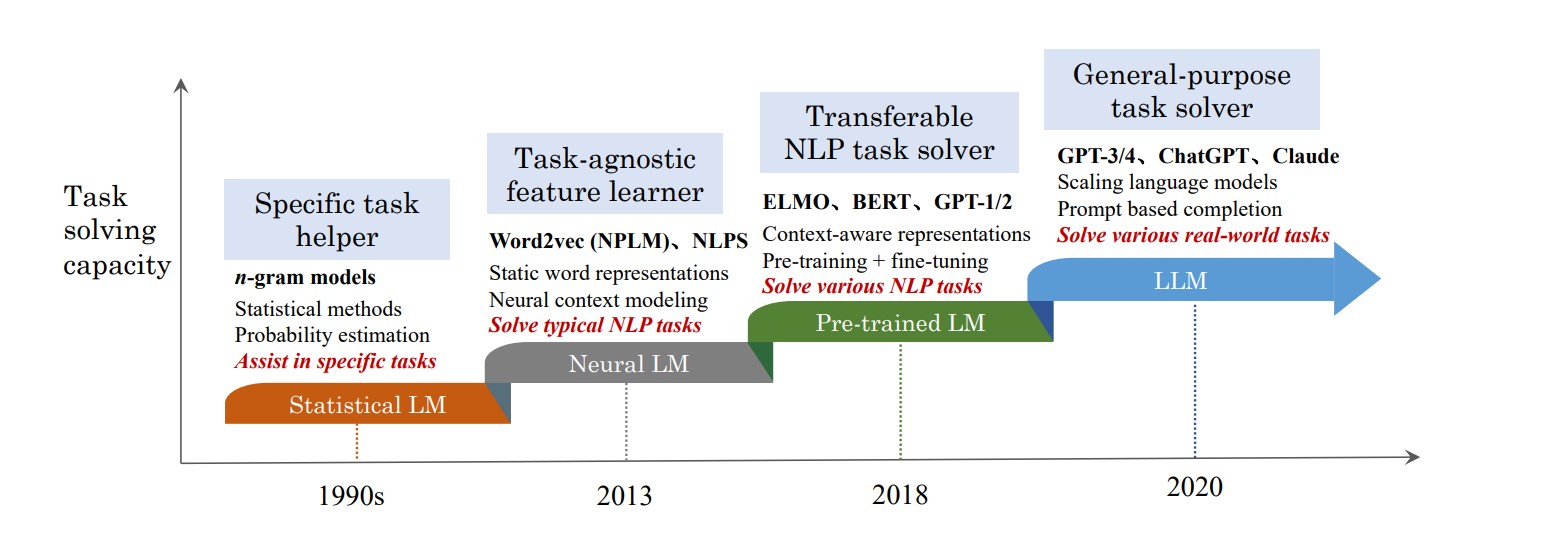
Current Improvement
Lately, deep studying structure transformer-based language fashions like BERT (Bidirectional Encoder Representations from Transformers) and GPT-1 (Generative Pre-trained Transformer) have been launched by Google and OpenAI, respectively. Such fashions use a bidirectional method to grasp the context from each instructions in a sentence and likewise generate coherent textual content by predicting the subsequent phrase in a sequence to enhance duties like query answering and sentiment evaluation.
With the current launch of ChatGPT Four and 4o, these fashions are getting extra subtle by including billions of parameters and setting new requirements in NLP duties.
Function of Giant Language Fashions in Trendy NLP
Giant Language Fashions are thought-about subsets of Pure Language Processing and their progress additionally turns into vital in Pure Language Processing (NLP). The fashions, corresponding to BERT and GPT-3 (improved model of GPT-1 and GPT-2), made NLP duties higher and polished.
This language technology mannequin requires giant quantities of knowledge units to coach they usually use architectures like transformers to keep up long-range dependencies in textual content. For instance, BERT can perceive the context of a phrase like “financial institution” to distinguish whether or not it refers to a monetary establishment or the aspect of a river.
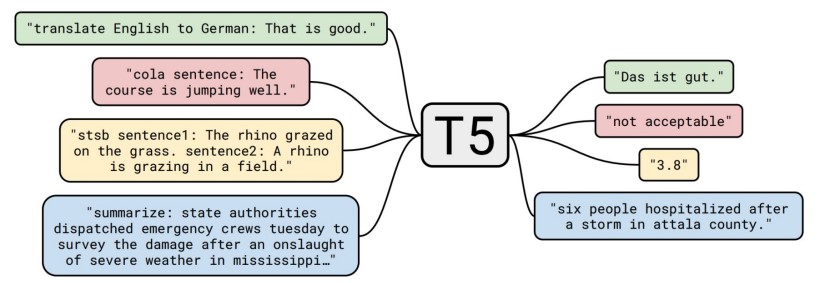
OpenAI’s GPT-3, with its 175 billion parameters, is one other outstanding instance. Producing coherent and contextually related textual content is simply made doable by OpenAI’s GPT-Three model. An instance of GPT-3’s functionality is its potential to finish sentences and paragraphs fluently, given a immediate.
LLM exhibits excellent efficiency in duties involving data-to-text like suggesting primarily based in your preferences, translating to any language, and even inventive writing. Giant datasets must be used to coach these fashions after which fine-tuning is required primarily based on the particular utility.
LLMs give rise to challenges as effectively whereas making nice progress. Issues like biases within the coaching set and the rising prices in computation want a mess of sources throughout intensive coaching and deployment.
Understanding The Working of LLMs – Transformer Structure
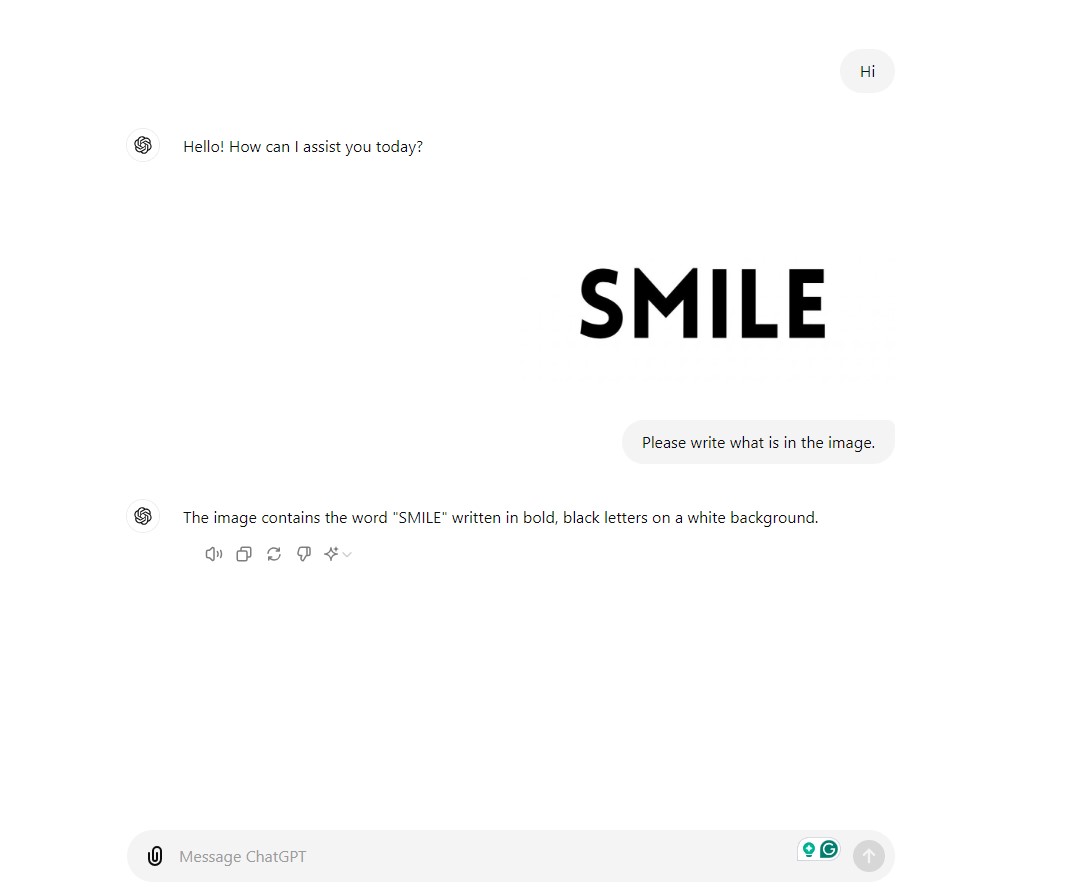
Deep studying structure Transformer serves because the cornerstone of recent LLMs and NLP. Not as a result of it’s comparatively environment friendly however as a result of potential to deal with sequential information and seize long-range dependencies which might be long-needed in Giant Language Fashions. Launched by Vaswani et al. within the seminal paper “Consideration Is All You Want”, the Transformer mannequin revolutionized how language fashions course of and generate textual content.
Transformer Structure
A transformer structure primarily consists of an encoder and a decoder. Each comprise self-attention mechanisms and feed-forward neural networks. Relatively than processing the info body by body, transformers can course of enter information in parallel and preserve long-range dependencies.
1. Tokenization
Each text-based enter is first tokenized into smaller items known as tokens. Tokenization converts every phrase into numbers representing a place in a predefined dictionary.
2. Embedding Layer
Tokens are handed via an embedding layer which then maps them to high-dimensional vectors to seize their semantic that means.
3. Positional Encoding
This step provides positional encoding to the embedding layer to assist the mannequin retain the order of tokens since transformers course of sequences in parallel.
4. Self-Consideration Mechanism
For each token, the self-attention mechanism generates and calculates three vectors:
- Question
- Key
- Worth
The dot-product of queries with keys determines the token relevance. The normalization of the outcomes is finished utilizing SoftMax after which utilized to the worth vectors to get context-aware phrase illustration.
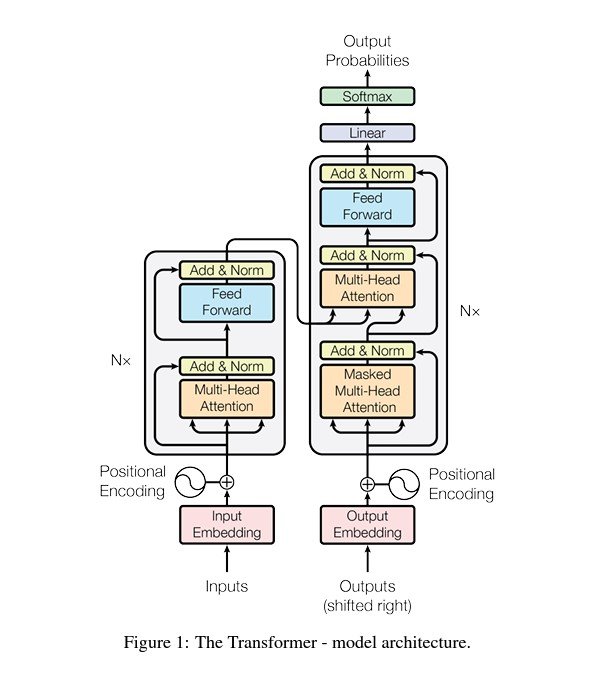
5. Multi-Head Consideration
Every head focuses on totally different enter sequences. The output is concatenated and linearly reworked leading to a greater understanding of complicated language buildings.
6. Feed-Ahead Neural Networks (FFNNs)
FFNNs course of every token independently. It consists of two linear transformations with a ReLU activation that provides non-linearity.
7. Encoder
The encoder processes the enter sequence and produces a context-rich illustration. It entails a number of layers of multi-head consideration and FFNNs.
8. Decoder
A decoder generates the output sequence. It processes the encoder’s output utilizing a further cross-attention mechanism, connecting sequences.
9. Output Era
The output is generated because the vector of logic for every token. The SoftMax layer is utilized to the output to transform them into likelihood scores. The token with the very best rating is the subsequent phrase in sequence.
Instance
For a easy translation process by the Giant Language Mannequin, the encoder processes the enter sentence within the supply language to assemble a context-rich illustration, and the decoder generates a translated sentence within the goal language in keeping with the output generated by the encoder and the earlier tokens generated.
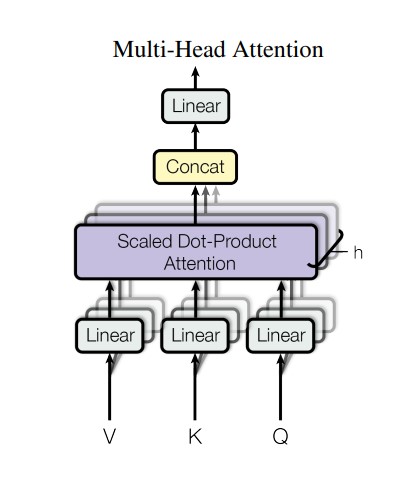
Customization and High-quality-Tuning of LLMs For A Particular Activity
It’s doable to course of whole sentences concurrently utilizing the transformer’s self-attention mechanism. That is the muse behind a transformer structure. Nevertheless, to additional enhance its effectivity and make it relevant to a sure utility, a standard transformer mannequin wants fine-tuning.
Steps For High-quality-Tuning
- Information Assortment: Acquire the info solely related to your particular process to make sure the mannequin achieves excessive accuracy.
- Information preprocessing: Based mostly in your dataset and its nature, normalize and tokenize textual content, take away cease phrases, and carry out morphological evaluation to arrange information for coaching.
- Deciding on Mannequin: Select an acceptable pre-trained mannequin (e.g., GPT-4, BERT) primarily based in your particular process necessities.
- Hyperparameter Tuning: For mannequin efficiency, alter the training charge, batch measurement, variety of epochs, and dropout charge.
- High-quality-Tuning: Apply strategies like LoRA or PEFT to fine-tune the mannequin on domain-specific information.
- Analysis and Deployment: Use metrics corresponding to accuracy, precision, recall, and F1 rating to judge the mannequin and implement the fine-tuned mannequin in your process.
Giant Language Fashions’ Use-Instances and Purposes
Medication
Giant Language Fashions mixed with Pc Imaginative and prescient have develop into a terrific software for radiologists. They’re utilizing LLMs for radiologic choice functions via the evaluation of pictures to allow them to have second opinions. Basic physicians and consultants additionally use LLMs like ChatGPT to get solutions to genetics-related questions from verified sources.
LLMs additionally automate the doctor-patient interplay, decreasing the danger of an infection or aid for these unable to maneuver. It was an incredible breakthrough within the medical sector particularly throughout pandemics like COVID-19. Instruments like XrayGPT automate the evaluation of X-ray pictures.
Schooling
Giant Language Fashions made studying materials extra interactive and simply accessible. With search engines like google and yahoo primarily based on AI fashions, academics can present college students with extra personalised programs and studying sources. Furthermore, AI instruments can provide one-on-one engagement and customised studying plans, corresponding to Khanmigo, a Digital Tutor by Khan Academy, which makes use of pupil efficiency information to make focused suggestions.
A number of research present that ChatGPT’s efficiency on the US Medical Licensing Examination (USMLE) was met or above the passing rating.
Finance
Danger evaluation, automated buying and selling, enterprise report evaluation, and assist reporting may be carried out utilizing LLMs. Fashions like BloombergGPT obtain excellent outcomes for information classification, entity recognition, and question-answering duties.
LLMs built-in with Buyer Relation Administration Techniques (CRMs) have develop into vital software for many companies as they automate most of their enterprise operations.
Different Purposes
- Builders are utilizing LLMs to put in writing and debug their codes.
- Content material creation turns into tremendous simple with LLMs. They’ll generate blogs or YouTube scripts very quickly.
- LLMs can take enter of agricultural land and site and supply particulars on whether or not it’s good for agriculture or not.
- Instruments like PDFGPT assist automate literature evaluations and extract related information or summarize textual content from the chosen analysis papers.
- Instruments like Imaginative and prescient Transformers (ViT) apply LLM rules to picture recognition which helps in medical imaging.
What’s Subsequent?
Earlier than LLMs, it wasn’t simple to grasp and convey machine language. Nevertheless, Giant Language Fashions are part of our on a regular basis life making it too good to be true that we are able to speak to computer systems. We will get extra personalised responses and perceive them due to their text-generation potential.
LLMs fill the long-awaited hole between machine and human communication. For the long run, these fashions want extra task-specific modeling and improved and correct outcomes. Getting extra correct and complex with time, think about what we are able to obtain with the convergence of LLMs, Pc Imaginative and prescient, and Robotics.
Learn extra associated subjects and blogs about LLMs and Deep Studying:



