Digital camera calibration is necessary to correct imaginative and prescient AI programs that analyse sports activities. It permits the mapping of their motion on a video body to actual motion on the sector, and thus the monitoring of the gap they cowl, the course, and the pace at which they transfer.
Homography is usually used for this function. It’s a geometric transformation that maps factors from one aircraft to a different, enabling the correction of perspective distortions. To use homography to a video body and precisely map participant actions to the sector, we have to know the corresponding factors between the video body and the sector.
Nonetheless, cameras at sporting occasions are sometimes positioned in numerous places and angles, they usually continuously pan, tilt, and zoom through the sport. This dynamic nature makes it difficult to manually decide the precise corresponding factors between the video body and the real-world area.
To beat this problem, we are going to practice an Ultralytics YOLOv8 keypoint detection mannequin to routinely establish particular attribute factors on the soccer area inside every video body. By detecting these factors within the video body and realizing their corresponding places on the precise area, we will set up the mandatory supply and goal factors required for homography calculation.
It will permit us to precisely map the participant actions captured within the video to their real-world positions on the sector, enabling complete evaluation and monitoring of their efficiency.
💡
Utilizing Keypoint Detection Fashions
Keypoint detection is a pc imaginative and prescient job that includes figuring out particular factors of curiosity in a picture or video. Keypoints symbolize distinctive options or landmarks, reminiscent of facial options, physique joints, or object corners. By precisely finding and monitoring keypoints, we will acquire insights into the construction, motion, and behavior of objects inside a scene.
Pitch Keypoints Dataset Labeling
The unique knowledge for this mission comes from the DFL – Bundesliga Knowledge Shootout Kaggle competitors. Video frames have been sampled each second and uploaded to Roboflow for annotation.
Earlier than we begin labeling the dataset, we have to decide which attribute factors of the pitch we need to detect. For the reason that digital camera can pan and zoom out and in freely, following the motion of the sport, we not often see the complete area. Due to this fact, we have to outline our factors densely sufficient in order that at any time – even when the digital camera is tightly following the motion – no less than 4 attribute factors are seen. This requirement comes from homography, which we are going to use to rework the attitude later on this tutorial. We in the end outlined 32 attribute factors, which have been then manually annotated on the uploaded pictures.
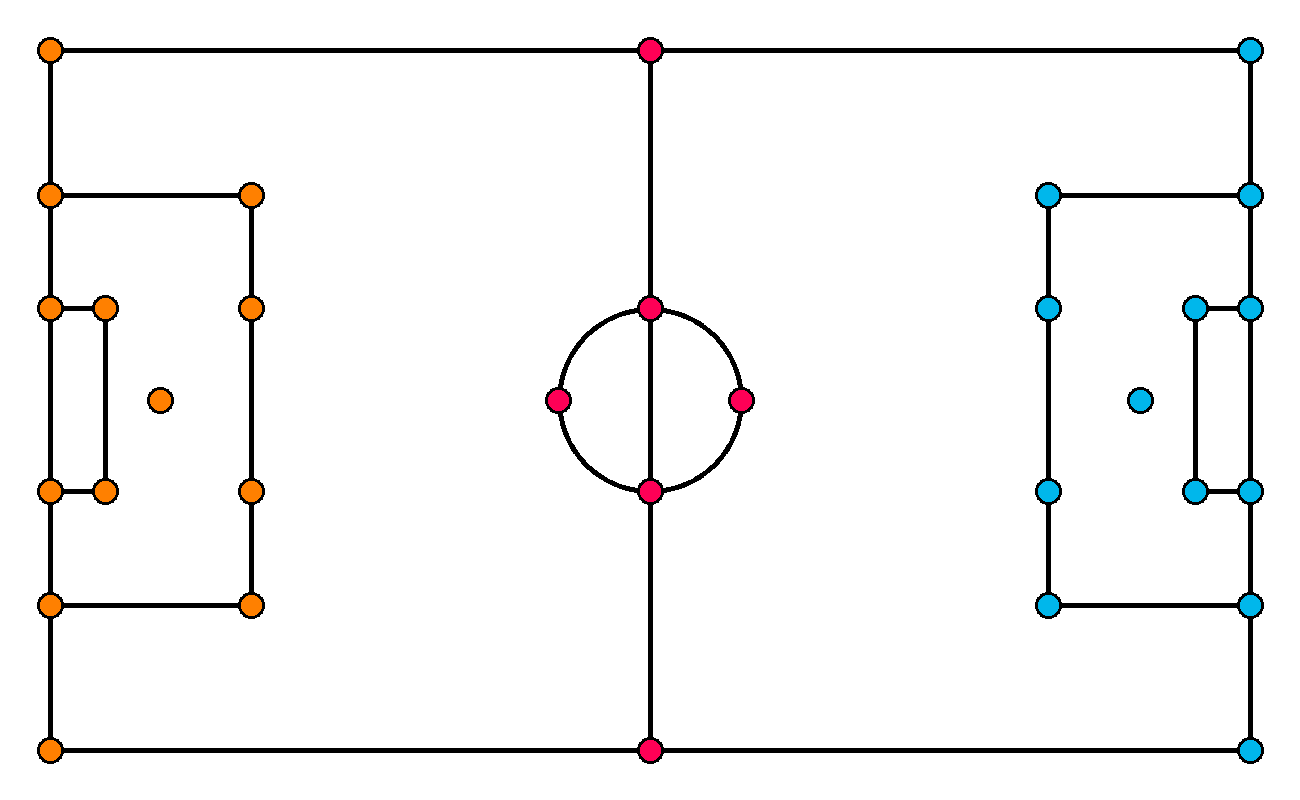
After finishing labeling, we utilized post-processing steps the place we rescaled every picture to 640×640 by stretching them to the brand new format. In our assessments, such a change led to raised outcomes in comparison with the letterbox.

Pitch Keypoints Detection Mannequin Coaching
Use the roboflow pip package deal to obtain the annotated dataset to Google Colab or your native machine. Set up the package deal in your Python surroundings after which observe the obtain directions. Make certain to obtain the dataset in YOLO format.
pip set up roboflowfrom roboflow import Roboflow rf = Roboflow(api_key=<ROBOFLOW_API_KEY>) workspace = rf.workspace("roboflow-jvuqo")
mission = workspace.mission("football-field-detection-f07vi")
model = mission.model(14)
dataset = model.obtain("yolov8")We then educated a YOLOv8x-pose mannequin for 500 epochs. Throughout coaching, we disabled mosaic augmentations. We seen that making use of it worsened the coaching outcomes. Relying on the {hardware} you may have, it might be needed to regulate your batch dimension. The mannequin was educated on an NVIDIA A100, the place a batch dimension of 48 was used.
pip set up ultralyticsyolo job=pose mode=practice mannequin=yolov8x-pose.pt
knowledge={dataset.location}/knowledge.yaml
batch=48 epochs=500 imgsz=640 mosaic=0.0After coaching was accomplished, the mannequin was uploaded to Roboflow, the place you may check the mannequin on-line.

Deploy Pitch Keypoints Detection
To load the educated mannequin, set up the inference and supervision packages utilizing:
pip set up inference supervisionThen, you may load the customized football-field-detection-f07vi/14 mannequin and run it on a single picture or video body:
import supervision as sv
from inference import get_model mannequin = get_model( model_id="football-field-detection-f07vi/14", api_key=<ROBOFLOW_API_KEY>
) picture = cv2.imread(<SOURCE_IMAGE_PATH>)
end result = mannequin.infer(picture, confidence=0.3)[0] keypoints = sv.KeyPoints.from_inference(end result)To visualise the inference outcomes, we are going to use one of many keypoint annotators accessible within the supervision library – VertexAnnotator.
import supervision as sv vertex_annotator = sv.VertexAnnotator(radius=12)
annotated_image = vertex_annotator.annotate(picture.copy(), keypoints)
The mannequin’s output at all times has a hard and fast dimension, in our case 32 factors, every with its personal confidence degree. When a keypoint just isn’t seen within the picture, the mannequin nonetheless returns a prediction for it, however with a low confidence degree. To acquire solely the supposed detections, we have to filter out the factors with low confidence.
As we will see, a few of the factors are within the anticipated places, whereas others are scattered randomly within the body, totally on the left and proper edges. By filtering out the factors with low confidence, we’re left with solely the factors which can be truly seen within the picture.
import supervision as sv
from inference import get_model mannequin = get_model( model_id="football-field-detection-f07vi/14", api_key=<ROBOFLOW_API_KEY>
) picture = cv2.imread(<SOURCE_IMAGE_PATH>)
end result = mannequin.infer(picture, confidence=0.3)[0] keypoints = sv.KeyPoints.from_inference(end result) filter = keypoints.confidence > 0.5
keypoints.xy = keypoints.xy[filter][np.newaxis]
keypoints.confidence = keypoints.confidence[filter][np.newaxis] vertex_annotator = sv.VertexAnnotator(radius=12)
annotated_image = vertex_annotator.annotate(picture.copy(), keypoints)
Use Homography to Convert Perspective
A homography is a projective transformation that maps factors from one aircraft to a different. It may be represented by a 3×3 matrix, which is commonly utilized in pc imaginative and prescient to appropriate perspective distortion or align pictures.
In our case, the variety of detected key factors on the soccer area adjustments because the digital camera strikes, so we used findHomography. This operate computes the homography matrix m that greatest maps the set of supply factors to the corresponding goal factors. A substitute for findHomography is getPerspectiveTransform, requiring precisely Four corresponding level pairs. In a mission like this, findHomography is a more sensible choice.
The ViewTransformer class permits us to reuse the calculated homography matrix m to rework new units of factors. It performs a perspective transformation on the enter factors utilizing the homography matrix.
The transform_points technique is the principle operate of the ViewTransformer class. It takes an array of 2D factors and applies the attitude transformation outlined by the homography matrix m, ensuing within the reworked factors.
import cv2
import numpy as np class ViewTransformer: def __init__(self, supply: np.ndarray, goal: np.ndarray) -> None: if supply.form != goal.form: increase ValueError( "Supply and goal will need to have the identical form.") if supply.form[1] != 2: increase ValueError( "Supply and goal factors should be 2D coordinates.") supply = supply.astype(np.float32) goal = goal.astype(np.float32) self.m, _ = cv2.findHomography(supply, goal) if self.m is None: increase ValueError( "Homography matrix couldn't be calculated.") def transform_points(self, factors: np.ndarray) -> np.ndarray: if factors.dimension == 0: return factors if factors.form[1] != 2: increase ValueError("Factors should be 2D coordinates.") factors = factors.reshape(-1, 1, 2).astype(np.float32) factors = cv2.perspectiveTransform(factors, self.m) return factors.reshape(-1, 2).astype(np.float32)Detections Perspective Transformation
It is time to check the ViewTransformer, however to do this, we’ll want detections that we will then switch from one aircraft to a different. For this function, we are going to use an object detection mannequin fine-tuned on the football-players-detection dataset to detect gamers and referees. As soon as once more, we are going to use inference to load the mannequin and visualise the outcomes.
import supervision as sv
from inference import get_model mannequin = get_model( model_id="football-players-detection-3zvbc/10", api_key=<ROBOFLOW_API_KEY>
) end result = mannequin.infer(body, confidence=0.3)[0] detections = sv.Detections.from_inference(end result) ellipse_annotator = sv.EllipseAnnotator(thickness=2)
body = ellipse_annotator.annotate(body, detections)
As talked about earlier, we want a set of level pairs from two planes to carry out perspective transformation utilizing homography. Our educated keypoints detection mannequin offers the factors on the video body, however we nonetheless lack factors reflecting the place of our 32 attribute factors on the precise area. You could find these within the SoccerFieldConfiguration positioned within the sports activities repository. To load them, set up the sports activities repository after which import the configuration.
pip set up -q git+https://github.com/roboflow/sports activities.gitfrom sports activities.configs.soccer import SoccerFieldConfiguration CONFIG = SoccerFieldConfiguration() end result = pitch_detection_model.infer(body, confidence=0.3)[0]
keypoints = sv.KeyPoints.from_inference(end result) filter = keypoints.confidence[0] > 0.5 transformer = ViewTransformer( supply=keypoints.xy[0][filter].astype(np.float32), goal=np.array(CONFIG.vertices)[filter].astype(np.float32)
) xy = detections.get_anchors_coordinates(anchor=sv.Place.BOTTOM_CENTER)
xy = transformer.transform_points(factors=xy)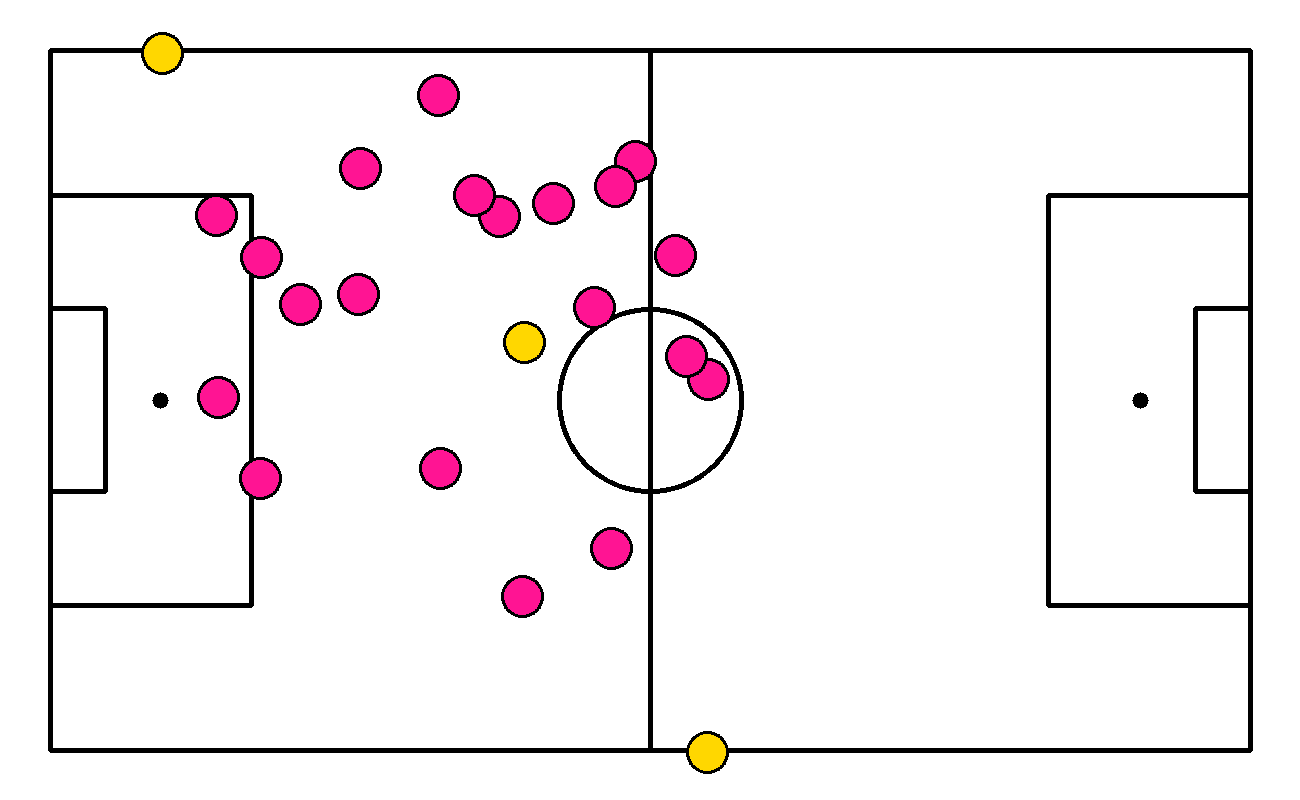
Conclusions
On this weblog publish, we explored the usage of YOLOv8 keypoint detection and homography for digital camera calibration in soccer footage. We coated the labeling course of for the dataset, the coaching of the keypoint detection mannequin, and the applying of homography for perspective transformation.
Digital camera calibration is simply one of many parts wanted to create a soccer AI. Try our sports activities repository to be taught what else will be performed by combining pc imaginative and prescient and sports activities.
Make certain to learn our different sport-themed weblog posts, particularly the one exhibiting the way to monitor a ball on a soccer pitch utilizing pc imaginative and prescient.


