
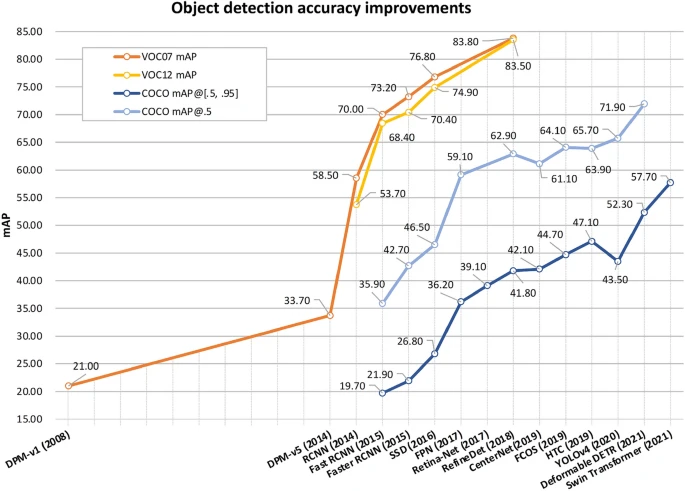
The world of pc imaginative and prescient modified ceaselessly 2011 onwards, when convolutional neural networks (CNNs) revolutionized object detection by offering a major leap in accuracy and effectivity in comparison with earlier strategies just like the Viola-Jones framework, which primarily relied on handcrafted options and boosted classifiers.
CNN-based fashions like Sooner R-CNN, YOLO, and CenterNet led to groundbreaking adjustments: Sooner R-CNN launched the idea of area proposal networks to streamline object detection, YOLO supplied real-time detection with spectacular velocity and accuracy, and CenterNet improved on keypoint-based object detection, making your entire course of extra sturdy and environment friendly. These developments laid the inspiration for the fashionable, extremely succesful object detection methods we see right now.
Rise of Transformers
![]()
The eye mechanism was first launched within the landmark paper “Consideration Is All You Want” by Vaswani et al. in 2017, which revolutionized the structure of neural networks by changing the standard recurrent constructions with a self-attention mechanism. This strategy allowed fashions to deal with totally different components of the enter sequence adaptively, main to higher understanding and parallelization of knowledge. This innovation laid the inspiration for the event of extremely correct fashions in numerous domains. Notably, the eye mechanism impressed the creation of Imaginative and prescient Transformers (ViT) and the Detection Transformer (DETR). DETR tailored the self-attention mechanism for object detection by treating object detection as a set prediction downside, enabling end-to-end detection with superior efficiency in comparison with conventional pipelines. ViT, then again, utilized self-attention to course of picture patches akin to phrases in a sequence, reworking pc imaginative and prescient duties and reaching state-of-the-art accuracy by leveraging the power to mannequin long-range dependencies successfully. Collectively, these developments introduced the transformative energy of the eye mechanism from NLP into pc imaginative and prescient, giving rise to fashions with unprecedented accuracy and effectivity.
Key Variations Between ViTs and CNNs:
- Function Extraction Method: CNNs use convolutional layers to create characteristic maps by making use of discovered filters, capturing native spatial patterns. ViTs cut up photos into patches and use self-attention to be taught world relationships amongst these patches, leading to a extra holistic characteristic extraction.
- Inductive Bias: CNNs have a powerful inductive bias in direction of native spatial correlations because of their use of fixed-size filters and weight sharing. ViTs, then again, have minimal inductive bias, permitting them to be taught relationships throughout your entire picture however usually requiring bigger datasets to generalize properly.
- Information Necessities: ViTs usually want extra coaching knowledge in comparison with CNNs to attain comparable efficiency, as they don’t inherently embed assumptions about native spatial constructions. CNNs are extra environment friendly on smaller datasets as a result of their design incorporates particular biases that align properly with pure picture constructions.
- International vs. Native Context: ViTs naturally mannequin long-range dependencies throughout a complete picture utilizing consideration, which helps in understanding world patterns and relationships. CNNs construct hierarchical options, which makes them environment friendly for capturing localized data however can battle with modeling your entire picture’s world context as successfully as ViTs.
Challenges and Improvements
Whereas transformers provide promising developments, they arrive with their very own set of challenges. The computational value of transformers is considerably larger than that of CNNs, significantly when coping with high-resolution photos. Nonetheless, improvements like sparse consideration, environment friendly transformers, and hybrid fashions that mix CNNs with transformers are serving to to mitigate these points. If you happen to take a look at the present cutting-edge object detection fashions, transformers are already proper there on the high.
Future Prospects
The way forward for object detection is transferring in direction of fashions that mix the strengths of transformers with different architectural developments to attain optimum efficiency. Self-supervised studying and multimodal transformers, which mix imaginative and prescient and language understanding, are additionally gaining traction, making object detection methods smarter and extra adaptable to various real-world purposes.
Transformers have set a brand new benchmark for what’s potential in object detection, pushing the boundaries of accuracy and effectivity. As analysis progresses, we are able to count on much more refined fashions that convey collectively one of the best of each transformers and conventional approaches, additional advancing the capabilities of object detection methods.


