Introduction
Agriculture has all the time been a cornerstone of human civilization, offering sustenance and livelihoods for billions worldwide. As expertise advances, we discover new and revolutionary methods to boost agricultural practices. One such development is utilizing Imaginative and prescient Transformers (ViTs) to categorise leaf illnesses in crops. On this weblog, we’ll discover how imaginative and prescient transformers in agriculture revolutionize by providing an environment friendly and correct resolution for figuring out and mitigating crop illnesses.
Cassava, or manioc or yuca, is a flexible crop with varied makes use of, from offering dietary staples to industrial purposes. Its hardiness and resilience make it an important crop for areas with difficult rising situations. Nevertheless, cassava crops are susceptible to varied illnesses, with CMD and CBSD being among the many most harmful.
CMD is attributable to a posh of viruses transmitted by whiteflies, resulting in extreme mosaic signs on cassava leaves. CBSD, however, is attributable to two associated viruses and primarily impacts storage roots, rendering them inedible. Figuring out these illnesses early is essential for stopping widespread crop injury and making certain meals safety. Imaginative and prescient Transformers, an evolution of the transformer structure initially designed for pure language processing (NLP), have confirmed extremely efficient in processing visible information. These fashions course of photographs as sequences of patches, utilizing self-attention mechanisms to seize intricate patterns and relationships within the information. Within the context of cassava leaf illness classification, ViTs are educated to establish CMD and CBSD by analyzing photographs of contaminated cassava leaves.
Studying Outcomes
- Understanding Imaginative and prescient Transformers and the way they’re utilized to agriculture, particularly for leaf illness classification.
- Be taught concerning the elementary ideas of the transformer structure, together with self-attention mechanisms, and the way these are tailored for visible information processing.
- Perceive the revolutionary use of Imaginative and prescient Transformers (ViTs) in agriculture, particularly for the early detection of cassava leaf illnesses.
- Achieve insights into some great benefits of Imaginative and prescient Transformers, corresponding to scalability and international context, in addition to their challenges, together with computational necessities and information effectivity.
This text was revealed as part of the Knowledge Science Blogathon.
Desk of contents
The Rise of Imaginative and prescient Transformers
Pc imaginative and prescient has made great strides lately, because of the event of convolutional neural networks (CNNs). CNNs have been the go-to structure for varied image-related duties, from picture classification to object detection. Nevertheless, Imaginative and prescient Transformers have risen as a powerful different, providing a novel method to processing visible data. Researchers at Google Analysis launched Imaginative and prescient Transformers in 2020 in a groundbreaking paper titled “An Picture is Value 16×16 Phrases: Transformers for Picture Recognition at Scale.” They tailored the transformer structure, initially designed for pure language processing (NLP), to the area of laptop imaginative and prescient. This adaptation has opened up new prospects and challenges within the discipline.
Using ViTs gives a number of benefits over conventional strategies, together with:
- Excessive Accuracy: ViTs excel in accuracy, permitting for the dependable detection and differentiation of leaf illnesses.
- Effectivity: As soon as educated, ViTs can course of photographs rapidly, making them appropriate for real-time illness detection within the discipline.
- Scalability: ViTs can deal with datasets of various sizes, making them adaptable to totally different agricultural settings.
- Generalization: ViTs can generalize to totally different cassava varieties and illness varieties, lowering the necessity for particular fashions for every state of affairs.
The Transformer Structure: A Transient Overview
Earlier than diving into Imaginative and prescient Transformers, it’s important to grasp the core ideas of the transformer structure. Transformers, initially designed for NLP, revolutionized language processing duties. The important thing options of transformers are self-attention mechanisms and parallelization, permitting for extra complete context understanding and sooner coaching.
On the coronary heart of transformers is the self-attention mechanism, which permits the mannequin to weigh the significance of various enter parts when making predictions. This mechanism, mixed with multi-head consideration layers, captures advanced relationships in information.
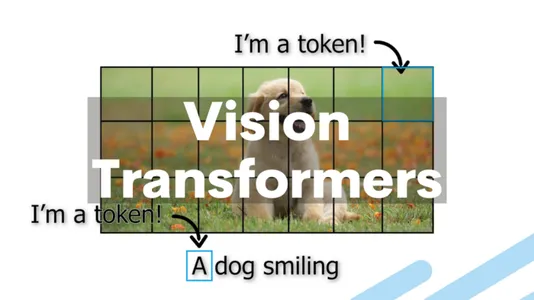
So, how do Imaginative and prescient Transformers apply this transformer structure to the area of laptop imaginative and prescient? The basic concept behind Imaginative and prescient Transformers is to deal with a picture as a sequence of patches, simply as NLP duties deal with textual content as a sequence of phrases. The transformer layers then course of every patch within the picture by embedding it right into a vector.
Key Elements of a Imaginative and prescient Transformer
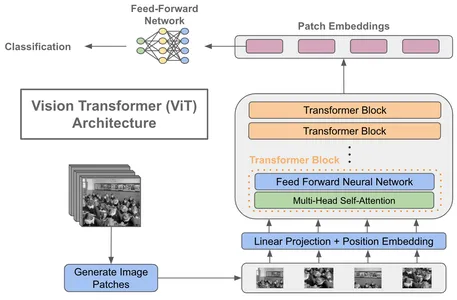
- Patch Embeddings: Divide a picture into fixed-size, non-overlapping patches, sometimes 16×16 pixels. Every patch is then linearly embedded right into a lower-dimensional vector.
- Positional Encodings: Add Positional encodings to the patch embeddings to account for the spatial association of patches. This permits the mannequin to study the relative positions of patches throughout the picture.
- Transformer Encoder: Imaginative and prescient Transformers include a number of transformer encoder layers like NLP transformers. Every layer performs self-attention and feed-forward operations on the patch embeddings.
- Classification Head: On the finish of the transformer layers, a classification head is added for duties like picture classification. It takes the output embeddings and produces class chances.
The introduction of Imaginative and prescient Transformers marks a major departure from CNNs, which depend on convolutional layers for characteristic extraction. By treating photographs as sequences of patches, Imaginative and prescient Transformers obtain state-of-the-art ends in varied laptop imaginative and prescient duties, together with picture classification, object detection, and even video evaluation.
Implementation
Dataset
The Cassava Leaf Illness dataset contains round 15,000 high-resolution photographs of cassava leaves exhibiting varied phases and levels of illness signs. Every picture is meticulously labeled to point the illness current, permitting for supervised machine studying and picture classification duties. Cassava illnesses exhibit distinct traits, resulting in their classification into a number of classes. These classes embrace Cassava Bacterial Blight (CBB), Cassava Brown Streak Illness (CBSD), Cassava Inexperienced Mottle (CGM), and Cassava Mosaic Illness (CMD). Researchers and information scientists leverage this dataset to coach and consider machine studying fashions, together with deep neural networks like Imaginative and prescient Transformers (ViTs).
Importing the Vital Libraries
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow.keras.layers as L
import tensorflow_addons as tfa
import glob, random, os, warnings
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns csvLoad the Dataset
image_size = 224
batch_size = 16
n_classes = 5 train_path = '/kaggle/enter/cassava-leaf-disease-classification/train_images'
test_path = '/kaggle/enter/cassava-leaf-disease-classification/test_images' df_train = pd.read_csv('/kaggle/enter/cassava-leaf-disease-classification/practice.csv', dtype = 'str') test_images = glob.glob(test_path + '/*.jpg')
df_test = pd.DataFrame(test_images, columns = ['image_path']) lessons = {0 : "Cassava Bacterial Blight (CBB)", 1 : "Cassava Brown Streak Illness (CBSD)", 2 : "Cassava Inexperienced Mottle (CGM)", 3 : "Cassava Mosaic Illness (CMD)", 4 : "Wholesome"}#import csvKnowledge Augmentation
def data_augment(picture): p_spatial = tf.random.uniform([], 0, 1.0, dtype = tf.float32) p_rotate = tf.random.uniform([], 0, 1.0, dtype = tf.float32) picture = tf.picture.random_flip_left_right(picture) picture = tf.picture.random_flip_up_down(picture) if p_spatial > .75: picture = tf.picture.transpose(picture) # Rotates if p_rotate > .75: picture = tf.picture.rot90(picture, ok = 3) # rotate 270º elif p_rotate > .5: picture = tf.picture.rot90(picture, ok = 2) # rotate 180º elif p_rotate > .25: picture = tf.picture.rot90(picture, ok = 1) # rotate 90º return picture#import csvKnowledge Generator
datagen = tf.keras.preprocessing.picture.ImageDataGenerator(samplewise_center = True, samplewise_std_normalization = True, validation_split = 0.2, preprocessing_function = data_augment) train_gen = datagen.flow_from_dataframe(dataframe = df_train, listing = train_path, x_col = 'image_id', y_col = 'label', subset = 'coaching', batch_size = batch_size, seed = 1, color_mode = 'rgb', shuffle = True, class_mode = 'categorical', target_size = (image_size, image_size)) valid_gen = datagen.flow_from_dataframe(dataframe = df_train, listing = train_path, x_col = 'image_id', y_col = 'label', subset = 'validation', batch_size = batch_size, seed = 1, color_mode = 'rgb', shuffle = False, class_mode = 'categorical', target_size = (image_size, image_size)) test_gen = datagen.flow_from_dataframe(dataframe = df_test, x_col = 'image_path', y_col = None, batch_size = batch_size, seed = 1, color_mode = 'rgb', shuffle = False, class_mode = None, target_size = (image_size, image_size))#import csvphotographs = [train_gen[0][0][i] for i in vary(16)]
fig, axes = plt.subplots(3, 5, figsize = (10, 10)) axes = axes.flatten() for img, ax in zip(photographs, axes): ax.imshow(img.reshape(image_size, image_size, 3)) ax.axis('off') plt.tight_layout()
plt.present()#import csv
Mannequin Constructing
learning_rate = 0.001
weight_decay = 0.0001
num_epochs = 1 patch_size = 7 # Dimension of the patches to be extract from the enter photographs
num_patches = (image_size // patch_size) ** 2
projection_dim = 64
num_heads = 4
transformer_units = [ projection_dim * 2, projection_dim,
] # Dimension of the transformer layers
transformer_layers = 8
mlp_head_units = [56, 28] # Dimension of the dense layers of the ultimate classifier def mlp(x, hidden_units, dropout_rate): for items in hidden_units: x = L.Dense(items, activation = tf.nn.gelu)(x) x = L.Dropout(dropout_rate)(x) return xPatch Creation
In our cassava leaf illness classification undertaking, we make use of customized layers to facilitate extracting and encoding picture patches. These specialised layers are instrumental in getting ready our information for processing by the Imaginative and prescient Transformer mannequin.
class Patches(L.Layer): def __init__(self, patch_size): tremendous(Patches, self).__init__() self.patch_size = patch_size def name(self, photographs): batch_size = tf.form(photographs)[0] patches = tf.picture.extract_patches( photographs = photographs, sizes = [1, self.patch_size, self.patch_size, 1], strides = [1, self.patch_size, self.patch_size, 1], charges = [1, 1, 1, 1], padding = 'VALID', ) patch_dims = patches.form[-1] patches = tf.reshape(patches, [batch_size, -1, patch_dims]) return patches plt.determine(figsize=(4, 4)) x = train_gen.subsequent()
picture = x[0][0] plt.imshow(picture.astype('uint8'))
plt.axis('off') resized_image = tf.picture.resize( tf.convert_to_tensor([image]), dimension = (image_size, image_size)
) patches = Patches(patch_size)(resized_image)
print(f'Picture dimension: {image_size} X {image_size}')
print(f'Patch dimension: {patch_size} X {patch_size}')
print(f'Patches per picture: {patches.form[1]}')
print(f'Components per patch: {patches.form[-1]}') n = int(np.sqrt(patches.form[1]))
plt.determine(figsize=(4, 4)) for i, patch in enumerate(patches[0]): ax = plt.subplot(n, n, i + 1) patch_img = tf.reshape(patch, (patch_size, patch_size, 3)) plt.imshow(patch_img.numpy().astype('uint8')) plt.axis('off') class PatchEncoder(L.Layer): def __init__(self, num_patches, projection_dim): tremendous(PatchEncoder, self).__init__() self.num_patches = num_patches self.projection = L.Dense(items = projection_dim) self.position_embedding = L.Embedding( input_dim = num_patches, output_dim = projection_dim ) def name(self, patch): positions = tf.vary(begin = 0, restrict = self.num_patches, delta = 1) encoded = self.projection(patch) + self.position_embedding(positions) return encoded#import csvPatches Layer (class Patches(L.Layer)
The Patches layer initiates our information preprocessing pipeline by extracting patches from uncooked enter photographs. These patches signify smaller, non-overlapping areas of the unique picture. The layer operates on batches of photographs, extracting specific-sized patches and reshaping them for additional processing. This step is crucial for enabling the mannequin to concentrate on fine-grained particulars throughout the picture, contributing to its skill to seize intricate patterns.
Visualization of Picture Patches
Following patch extraction, we visualize their influence on the picture by displaying a pattern picture overlaid with a grid showcasing the extracted patches. This visualization gives insights into how the picture is split into these patches, highlighting the patch dimension and the variety of patches extracted from every picture. It aids in understanding the preprocessing stage and units the stage for subsequent evaluation.
Patch Encoding Layer (class PatchEncoder(L.Layer)
As soon as the patches are extracted, they endure additional processing by way of the PatchEncoder layer. This layer is pivotal in encoding the data contained inside every patch. It consists of two key parts: a linear projection that enhances the patch’s options and a place embedding that provides spatial context. The ensuing enriched patch representations are essential for the Imaginative and prescient Transformer’s evaluation and studying, finally contributing to the mannequin’s effectiveness in correct illness classification.
The customized layers, Patches and PatchEncoder, are integral to our information preprocessing pipeline for cassava leaf illness classification. They allow the mannequin to concentrate on picture patches, enhancing its capability to discern pertinent patterns and options important for exact illness classification. This course of considerably bolsters the general efficiency of our Imaginative and prescient Transformer mannequin.
def vision_transformer(): inputs = L.Enter(form = (image_size, image_size, 3)) # Create patches. patches = Patches(patch_size)(inputs) # Encode patches. encoded_patches = PatchEncoder(num_patches, projection_dim)(patches) # Create a number of layers of the Transformer block. for _ in vary(transformer_layers): # Layer normalization 1. x1 = L.LayerNormalization(epsilon = 1e-6)(encoded_patches) # Create a multi-head consideration layer. attention_output = L.MultiHeadAttention( num_heads = num_heads, key_dim = projection_dim, dropout = 0.1 )(x1, x1) # Skip connection 1. x2 = L.Add()([attention_output, encoded_patches]) # Layer normalization 2. x3 = L.LayerNormalization(epsilon = 1e-6)(x2) # MLP. x3 = mlp(x3, hidden_units = transformer_units, dropout_rate = 0.1) # Skip connection 2. encoded_patches = L.Add()([x3, x2]) # Create a [batch_size, projection_dim] tensor. illustration = L.LayerNormalization(epsilon = 1e-6)(encoded_patches) illustration = L.Flatten()(illustration) illustration = L.Dropout(0.5)(illustration) # Add MLP. options = mlp(illustration, hidden_units = mlp_head_units, dropout_rate = 0.5) # Classify outputs. logits = L.Dense(n_classes)(options) # Create the mannequin. mannequin = tf.keras.Mannequin(inputs = inputs, outputs = logits) return mannequin decay_steps = train_gen.n // train_gen.batch_size
initial_learning_rate = learning_rate lr_decayed_fn = tf.keras.experimental.CosineDecay(initial_learning_rate, decay_steps) lr_scheduler = tf.keras.callbacks.LearningRateScheduler(lr_decayed_fn) optimizer = tf.keras.optimizers.Adam(learning_rate = learning_rate) mannequin = vision_transformer() mannequin.compile(optimizer = optimizer, loss = tf.keras.losses.CategoricalCrossentropy(label_smoothing = 0.1), metrics = ['accuracy']) STEP_SIZE_TRAIN = train_gen.n // train_gen.batch_size
STEP_SIZE_VALID = valid_gen.n // valid_gen.batch_size earlystopping = tf.keras.callbacks.EarlyStopping(monitor = 'val_accuracy', min_delta = 1e-4, persistence = 5, mode = 'max', restore_best_weights = True, verbose = 1) checkpointer = tf.keras.callbacks.ModelCheckpoint(filepath = './mannequin.hdf5', monitor = 'val_accuracy', verbose = 1, save_best_only = True, save_weights_only = True, mode = 'max') callbacks = [earlystopping, lr_scheduler, checkpointer] mannequin.match(x = train_gen, steps_per_epoch = STEP_SIZE_TRAIN, validation_data = valid_gen, validation_steps = STEP_SIZE_VALID, epochs = num_epochs, callbacks = callbacks)
#import csvCode Clarification
This code defines a customized Imaginative and prescient Transformer mannequin tailor-made for our cassava illness classification job. It encapsulates a number of Transformer blocks, every consisting of multi-head consideration layers, skip connections, and multi-layer perceptrons (MLPs). The outcome is a strong mannequin able to capturing intricate patterns in cassava leaf photographs.
Firstly, the vision_transformer() perform takes heart stage by defining the architectural blueprint of our Imaginative and prescient Transformer. This perform outlines how the mannequin processes and learns from cassava leaf photographs, enabling it to categorise illnesses exactly.
To additional optimize the coaching course of, we implement a studying price scheduler. This scheduler employs a cosine decay technique, dynamically adjusting the training price because the mannequin learns. This dynamic adaptation enhances the mannequin’s convergence, permitting it to succeed in its peak efficiency effectively.
We proceed with mannequin compilation as soon as our mannequin’s structure and coaching technique are set. Throughout this part, we specify important parts such because the loss capabilities, optimizers, and analysis metrics. These parts are rigorously chosen to make sure that our mannequin optimizes its studying course of, making correct predictions.
Lastly, the effectiveness of our mannequin’s coaching is ensured by making use of coaching callbacks. Two essential callbacks come into play: early stopping and mannequin checkpointing. Early stopping displays the mannequin’s efficiency on validation information and intervenes when enhancements stagnate, thus stopping overfitting. Concurrently, mannequin checkpointing data the best-performing model of our mannequin, permitting us to protect its optimum state for future use.
Collectively, these parts create a holistic framework for creating, coaching, and optimizing our Imaginative and prescient Transformer mannequin, a key step in our journey towards correct cassava leaf illness classification.
Purposes of ViTs in Agriculture
The appliance of Imaginative and prescient Transformers in cassava farming extends past analysis and novelty; it gives sensible options to urgent challenges:
- Early Illness Detection: ViTs allow early detection of CMD and CBSD, permitting farmers to take immediate motion to forestall the unfold of illnesses and decrease crop losses.
- Useful resource Effectivity: With ViTs, assets corresponding to time and use labor extra effectively, as automated illness detection reduces the necessity for guide inspection of each cassava plant.
- Precision Agriculture: Combine ViTs with different applied sciences like drones and IoT units for precision agriculture, the place illness hotspots are recognized and handled exactly.
- Improved Meals Safety: By mitigating the influence of illnesses on cassava yields, ViTs contribute to enhanced meals safety in areas the place cassava is a dietary staple.
Benefits of Imaginative and prescient Transformers
Imaginative and prescient Transformers supply a number of benefits over conventional CNN-based approaches:
- Scalability: Imaginative and prescient Transformers can deal with photographs of various resolutions with out requiring modifications to the mannequin structure. This scalability is especially invaluable in real-world purposes the place photographs come in several sizes.
- World Context: The self-attention mechanism in Imaginative and prescient Transformers permits them to seize international context successfully. That is essential for duties like recognizing objects in cluttered scenes.
- Fewer Architectural Elements: Not like CNNs, Imaginative and prescient Transformers don’t require advanced architectural parts like pooling layers and convolutional filters. This simplifies mannequin design and upkeep.
- Switch Studying: Imaginative and prescient Transformers may be pretrained on massive datasets, making them glorious candidates for switch studying. Pretrained fashions may be fine-tuned for particular duties with comparatively small quantities of task-specific information.
Challenges and Future Instructions
Whereas Imaginative and prescient Transformers have proven exceptional progress, in addition they face a number of challenges:
- Computational Sources: Coaching massive Imaginative and prescient Transformer fashions requires substantial computational assets, which could be a barrier for smaller analysis groups and organizations.
- Knowledge Effectivity: Imaginative and prescient Transformers may be data-hungry, and reaching sturdy efficiency with restricted information may be difficult. Growing methods for extra data-efficient coaching is a urgent concern.
- Interpretability: Transformers are sometimes criticized for his or her black-box nature. Researchers are engaged on strategies to enhance the interpretability of Imaginative and prescient Transformers, particularly in safety-critical purposes.
- Actual-time Inference: Reaching real-time inference with massive Imaginative and prescient Transformer fashions may be computationally intensive. Optimizations for sooner inference are an lively analysis space.
Conclusion
Imaginative and prescient Transformers rework cassava farming by providing correct and environment friendly options for leaf illness classification. Their skill to course of visible information, coupled with developments in information assortment and mannequin coaching, holds great potential for safeguarding cassava crops and making certain meals safety. Whereas challenges stay, ongoing analysis and sensible purposes drive driving adoption of ViTs in cassava farming. Continued innovation and collaboration will rework ViTs into a useful software for cassava farmers worldwide, as they contribute to sustainable farming practices and scale back crop losses attributable to devastating leaf illnesses.
Key Takeaways
- Imaginative and prescient Transformers (ViTs) adapt transformer structure for laptop imaginative and prescient, processing photographs as sequences of patches.
- ViTs, initially designed for laptop imaginative and prescient, are actually being utilized to agriculture to handle challenges just like the early detection of leaf illnesses.
- Deal with challenges like computational assets and information effectivity, making ViTs a promising expertise for the way forward for laptop imaginative and prescient.
Often Requested Questions
A1: Imaginative and prescient Transformers, or ViTs, are deep studying structure that adapts the transformer mannequin from pure language processing to course of and perceive visible information. They deal with photographs as sequences of patches and have proven spectacular ends in varied laptop imaginative and prescient duties.
A2: Whereas CNNs depend on convolutional layers for characteristic extraction in a grid-like style, Imaginative and prescient Transformers course of photographs as sequences of patches and use self-attention mechanisms. This permits ViTs to seize international context and work successfully with photographs of various sizes.
A3: Use Imaginative and prescient Transformers in varied purposes, together with picture classification, object detection, semantic segmentation, video evaluation, and even autonomous autos. Their versatility makes them appropriate for a lot of laptop imaginative and prescient duties.
A4: Coaching massive Imaginative and prescient Transformer fashions may be computationally intensive and will require vital assets. Nevertheless, researchers are engaged on optimizations for sooner coaching and inference, making them extra sensible.
The media proven on this article just isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.



