Roboflow Inference is an open supply mission you should utilize to run inference on state-of-the-art pc imaginative and prescient fashions. With no prior data of machine studying or device-specific deployment, you possibly can deploy a pc imaginative and prescient mannequin to a spread of units and environments.
Utilizing Inference, you possibly can deploy object detection, classification, segmentation, and a spread of basis fashions (i.e. SAM and CLIP) for manufacturing use. With an non-obligatory Enterprise license, you possibly can entry extra options like system administration capabilities and cargo balancer assist.
On this information, we’re going to present you the way to deploy Roboflow Inference to Azure. We’ll deploy a digital machine on Azure, set up Docker, set up Inference, then run inference domestically on a pc imaginative and prescient mannequin skilled on Roboflow.
With out additional ado, let’s get began!
Deploy Roboflow Inference on Azure
To get began, you’ll need a Microsoft Azure account. Additionally, you will want a Roboflow account with a skilled mannequin. Learn to practice a pc imaginative and prescient mannequin on Roboflow. Alternatively, you possibly can deploy a basis mannequin like SAM or CLIP, for which you don’t want a skilled mannequin.
For this information, we will likely be deploying a photo voltaic panel object detection mannequin that processes aerial imagery in bulk. We’ll use an Azure Digital Machine to run inference.
Step #1: Create an Azure Digital Machine
Go to the Microsoft Azure dashboard and seek for “Digital Machines” within the product search bar. Click on “Create” to create a digital machine:
Select to create an “Azure digital machine” within the dropdown that seems. Subsequent, you’ll be requested to configure your digital machine. The way you configure the digital machine depends on how you intend to make use of the digital machine so we is not going to cowl specifics on this tutorial.
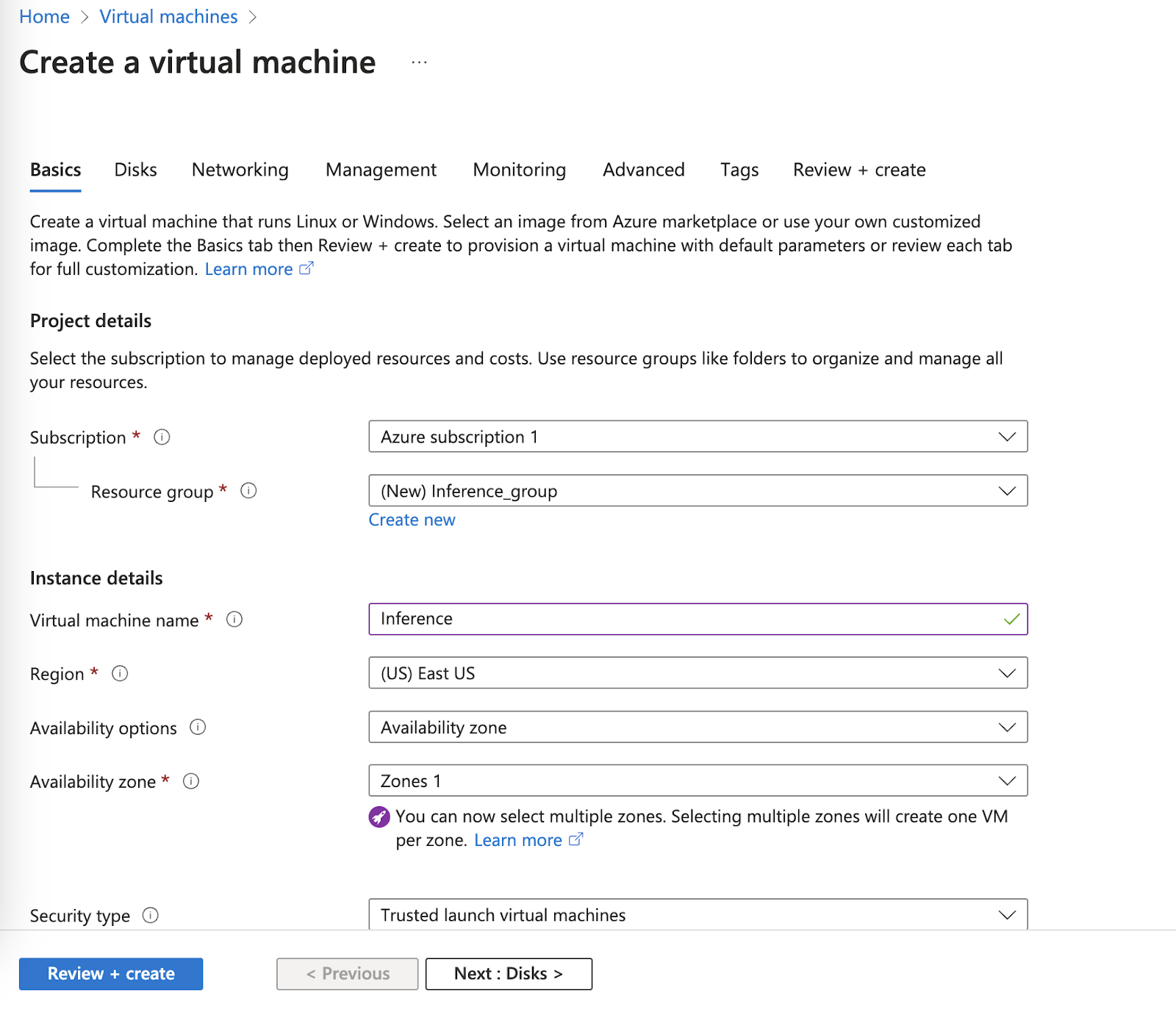
Roboflow Inference can run on each CPU (x86 and ARM) and NVIDIA GPU units. For the perfect efficiency in manufacturing, we suggest deploying a machine with an NVIDIA GPU. For testing, use the system that is sensible given your wants.
On this information, we’ll deploy on a CPU system.
When you verify deployment of your digital machine, Azure will present the progress of the deployment:

When your digital machine is prepared, a pop up will seem. Click on “View useful resource” to view the digital machine. Or, return to the Digital Machines homepage and choose your newly-deployed digital machine.
Step #2: Signal into Digital Machine
To signal into your digital machine, first click on “Join”.

Select the authentication methodology that you simply want.
On this information, we’ll SSH into our digital machine by way of the command line. If you SSH into the digital machine, you will notice the usual shell through which to write down instructions.
Step #3: Set up Roboflow Inference
Now now we have a digital machine prepared, we will set up Roboflow Inference. On this information, we’re deploying on a machine with a CPU. Thus, we’ll stroll via the CPU set up directions. If you’re deploying on a GPU, discuss with the Roboflow Inference Docker set up directions to put in Inference.
Whether or not you’re utilizing a GPU or CPU, there are three steps to put in Inference:
- Set up Docker.
- Pull the Inference Docker container on your machine sort.
- Run the Docker container.
The Docker set up directions differ by working system. To search out out the working system your machine is utilizing, run the next command:
lsb_release -aOn this instance, we’re deploying on a Ubuntu machine. Thus, we have to observe the Ubuntu Docker set up directions. Comply with the Docker set up directions on your machine.
After you have put in Docker, you possibly can set up Inference. Right here is the command to put in Inference on a GPU:
docker pull roboflow/roboflow-inference-server-cpuYou will note an interactive output that exhibits the standing of downloading the Docker container.
As soon as the Docker container has downloaded, you possibly can run Inference utilizing the next command:
docker run --net=host roboflow/roboflow-inference-server-cpu:newestBy default, Inference is deployed at http://localhost:9001.
Step #4: Check Mannequin
All inferences are run on-device for optimum efficiency. Now that now we have Inference operating, we will begin loading a mannequin to make use of.
To load a mannequin, we have to make a HTTP request to Inference. The primary time we make a HTTP request, Inference will obtain and arrange the weights for the mannequin on which you wish to run inference. On this information, we’ll deploy a photo voltaic panel mannequin skilled on Roboflow.
To make a request, we’ll want just a few items of knowledge:
- Our Roboflow API key
- Our mannequin ID
- Our mannequin model
To retrieve this info, go to your Roboflow dashboard and choose a mission. Then, click on “Variations” within the sidebar of the mission and choose the model you wish to deploy.

Create a brand new Python file and add the next code:
import requests dataset_id = ""
version_id = "1"
image_url = "" api_key = "ROBOFLOW_API_KEY"
confidence = 0.5 url = f"http://localhost:9001/{dataset_id}/{version_id}" params = { "api_key": api_key, "confidence": confidence, "picture": image_url,
} res = requests.publish(url, params=params) print(res.json())Within the code above, exchange the next values with the knowledge accessible on the Model web page we opened earlier:
- dataset_id: The ID of your dataset (on this instance, “construction-safety-dkale”).
- version_id: The model you wish to deploy (on this instance, 1).
- image_url: The picture on which you wish to run inference. This could be a native path or a URL.
- api_key: Your Roboflow API key. Learn to retrieve your Roboflow API key.
Now we’re able to run inference. The script above will run inference on a picture and return a JSON illustration of the entire predictions returned by the mannequin.
The next tutorials present just a few of the numerous tasks you possibly can construct with Inference:
Conclusion
On this information, now we have deployed a pc imaginative and prescient mannequin to Azure with Roboflow Inference. We created an Azure digital machine through which to run our mannequin, put in Roboflow Inference by way of Docker, and ran inference on a picture.
Now that you’ve got Inference arrange, the subsequent step is to configure your server in keeping with your wants. For instance, you can deploy Inference to a public area behind authentication or configure entry in a VPC.
Contact the Roboflow gross sales workforce to be taught extra about Roboflow Enterprise choices.



