All through 2023 there have been vital developments towards constructing multi-modal language fashions. To date, the main focus has been on offering fashions that permit textual content and picture enter so you possibly can ask questions on a picture. Different experiments contain speech, too. This yr alone, OpenAI has launched GPT-4(V)ision and Google has launched Bard and accompanying imaginative and prescient capabilities.
On October fifth, 2023, LLaVA-1.5 was launched, an open-source, multi-modal language mannequin. This mannequin, the following iteration of LLaVA, could be educated on one 8-A100 GPU. This mannequin performs nicely in picture description and visible QA and reveals progress in making extra open-source multi-modal language fashions.
On this information, we’re going to share our first impressions with LLaVA-1.5, specializing in its picture capabilities. We’ll ask a sequence of inquiries to LLaVA-1.5 based mostly on our learnings evaluating Bard and GPT-4(V).
With out additional ado, let’s get began!
What’s LLaVA-1.5?
LLaVA-1.5 is an open-source, multi-modal language mannequin. You possibly can ask LLaVA-1.5 questions in textual content and optionally present a picture as context on your query. The code for LLaVA-1.5 was launched to accompany the “Improved Baselines with Visible Instruction Tuning” paper. Use the demo.
The authors of the paper observe within the summary “With easy modifications to LLaVA, particularly, utilizing CLIP-ViT-L-336px with an MLP projection and including academic-task-oriented VQA information with easy response formatting prompts, we set up stronger baselines that obtain state-of-the-art [performance] throughout 11 benchmarks.”
LLaVA-1.5 is obtainable to be used in a web based demo playground, with which you’ll experiment at present. That is in distinction to GPT-4(V)ision, which remains to be rolling out and solely accessible on the paid GPT-Four tier of choices from OpenAI.
Check #1: Zero Shot Object Detection
One of many first exams we run when evaluating a brand new multi-modal mannequin is to ask for the coordinates of an object in a picture. This check permits us to judge the extent to which a mannequin can carry out zero-shot object detection, a sort of object detection the place a mannequin goals to determine an object with out being fine-tuned for the aim of figuring out that object.
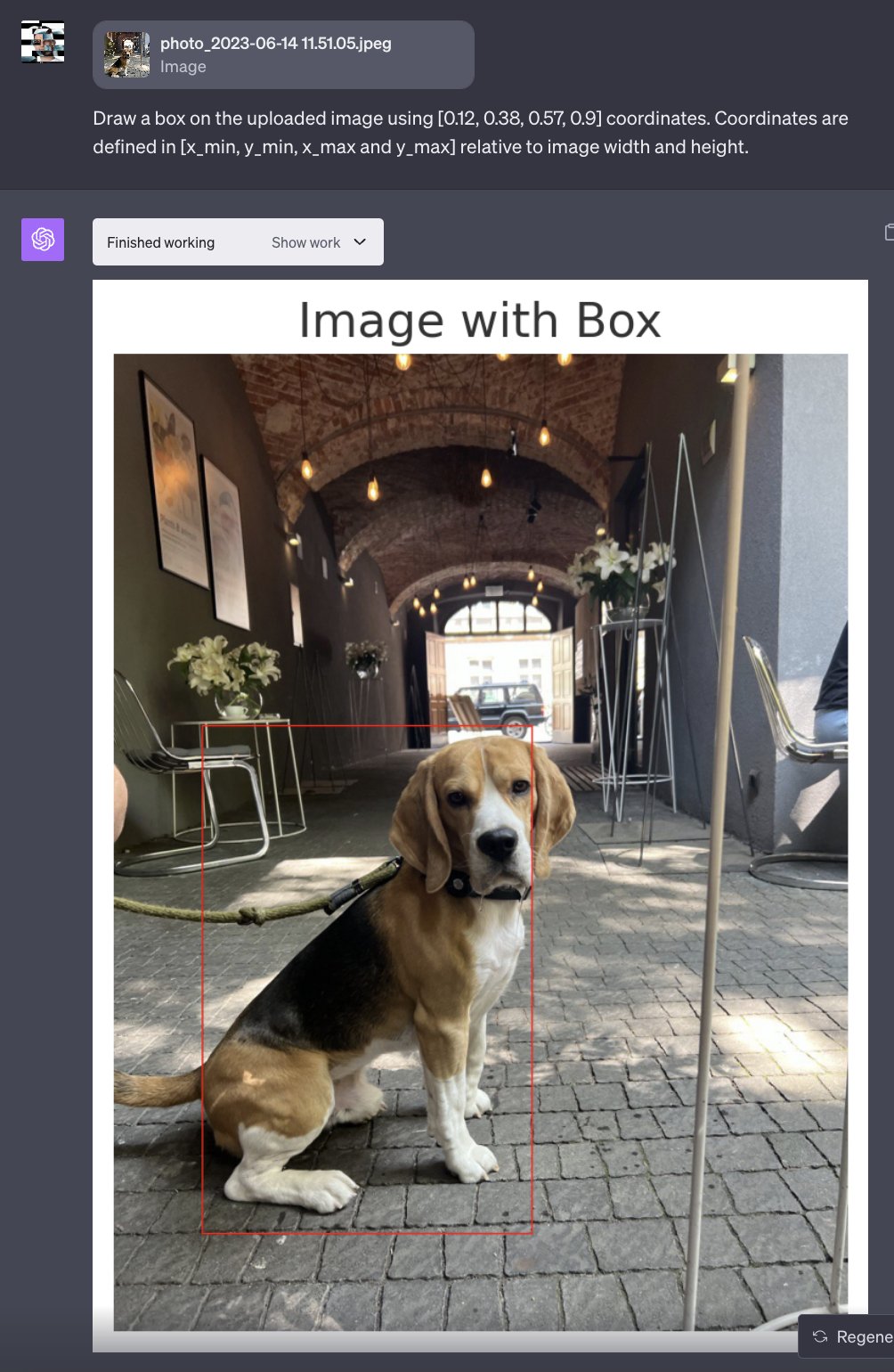
We examined LLaVA-1.5’s skill to detect a canine and a straw in two separate photographs. In each instances, LLaVA-1.5 was in a position to efficiently determine the thing.
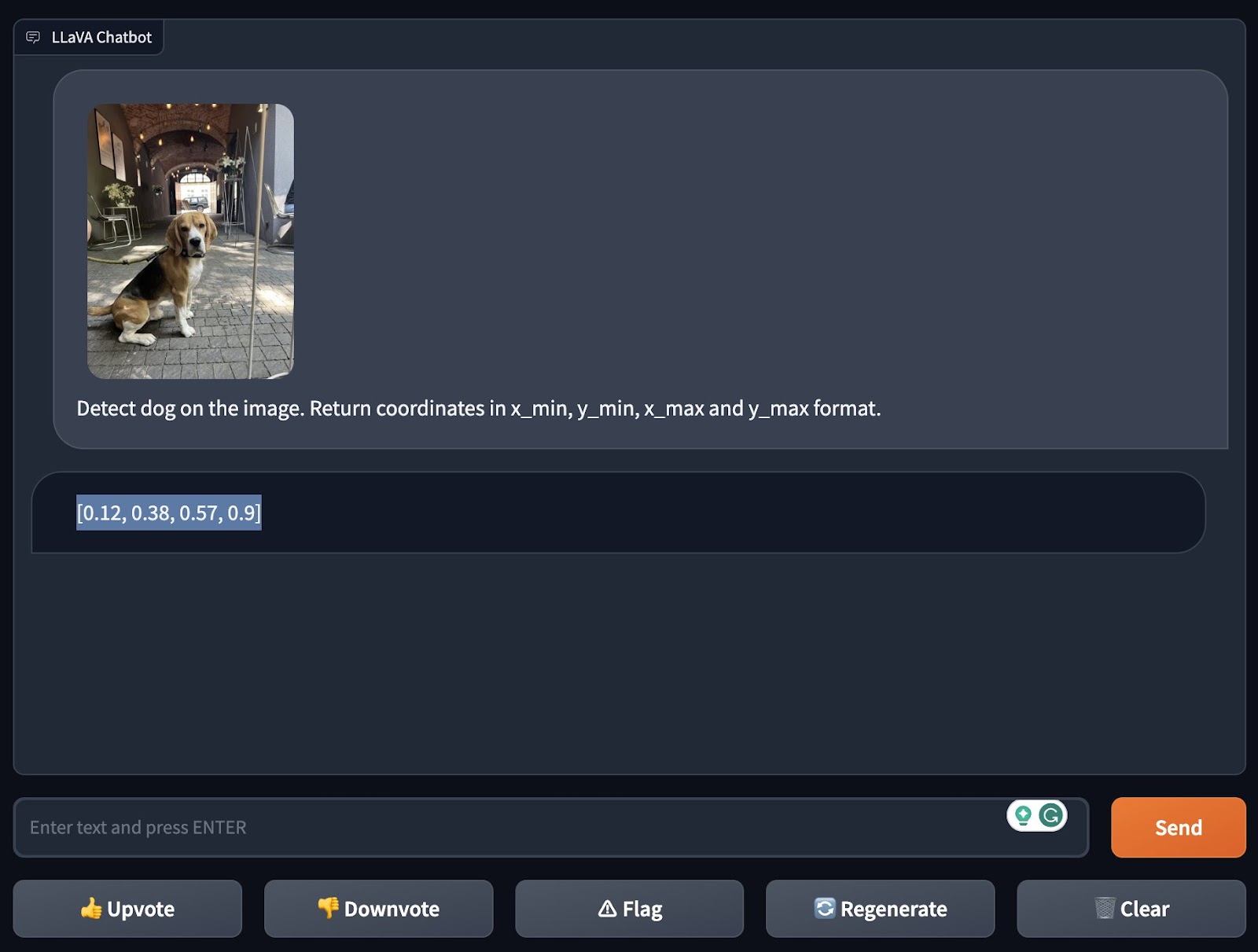
We used ChatGPT’s Code Interpreter to attract a bounding field across the coordinates of the canine to visualise the coordinates:
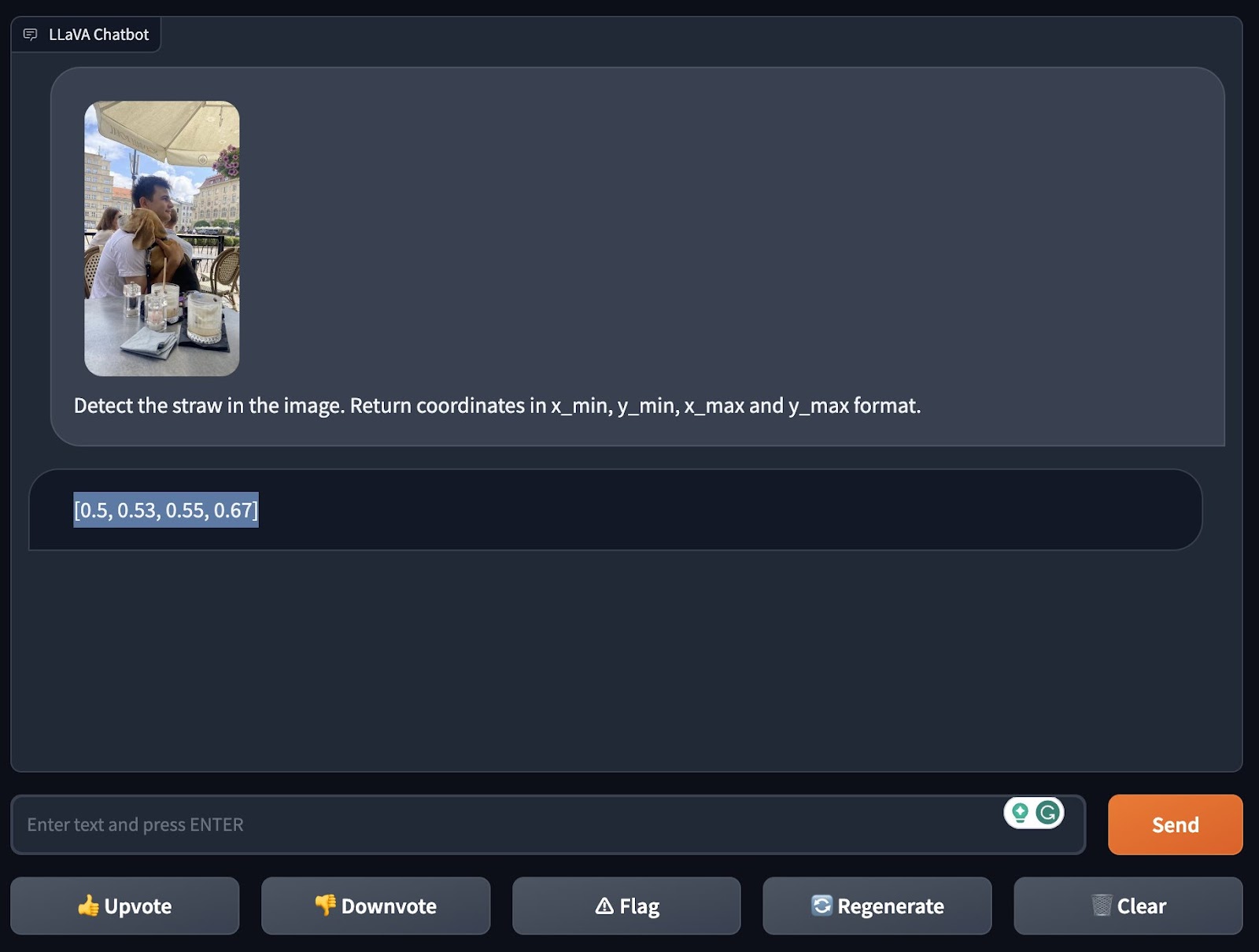

Check #2: Picture Understanding
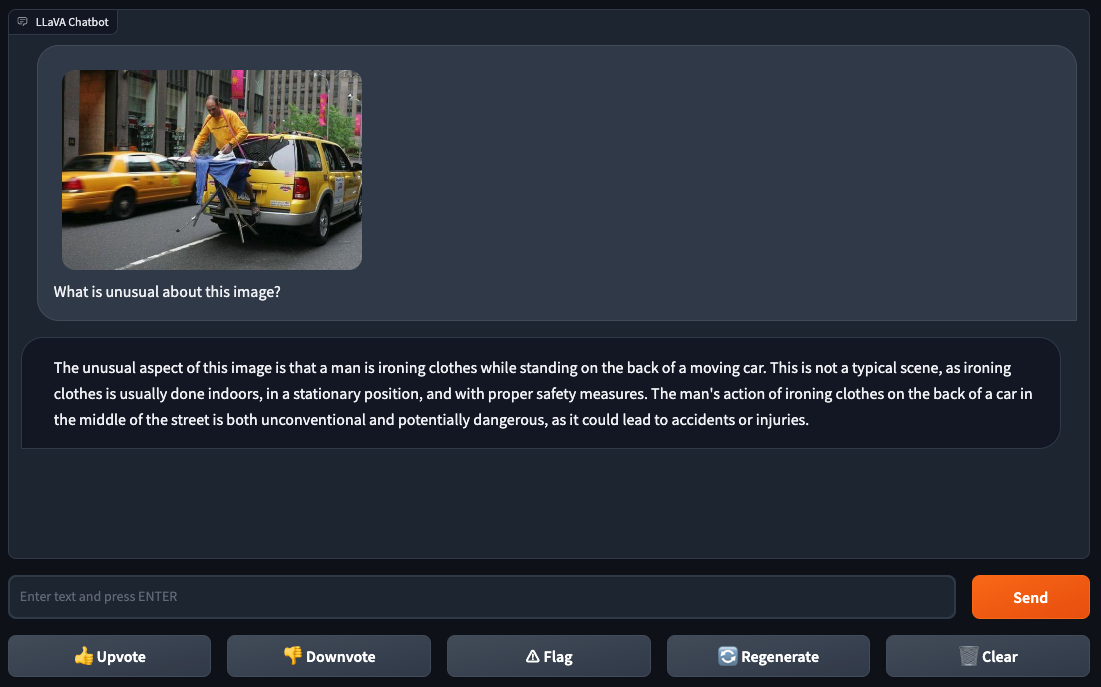
In our weblog submit the place we examined GPT-4(V)ision, we requested a query a couple of meme as a proxy for understanding how the mannequin performs with nuanced context. We determined to do that check with a twist: as an alternative of a meme, we might use a picture with an odd defining attribute.
We uploaded a photograph of a picture the place an individual is ironing garments on an ironing board that’s connected to the again of a yellow automobile in a metropolis. The ironing board is comparatively flat regardless of being hooked onto a yellow automobile in a approach that isn’t instantly apparent upon human inspection.
We requested LLaVA-1.5 “What’s uncommon about this picture?”, to which the mannequin responded with a solution noting that “ironing garments is normally completed indoors, in a stationary place, and with correct security measures”. LLaVA-1.5 then goes on to explain that “ironing garments on the again of a automobile in the midst of the road is each unconventional and probably harmful”.
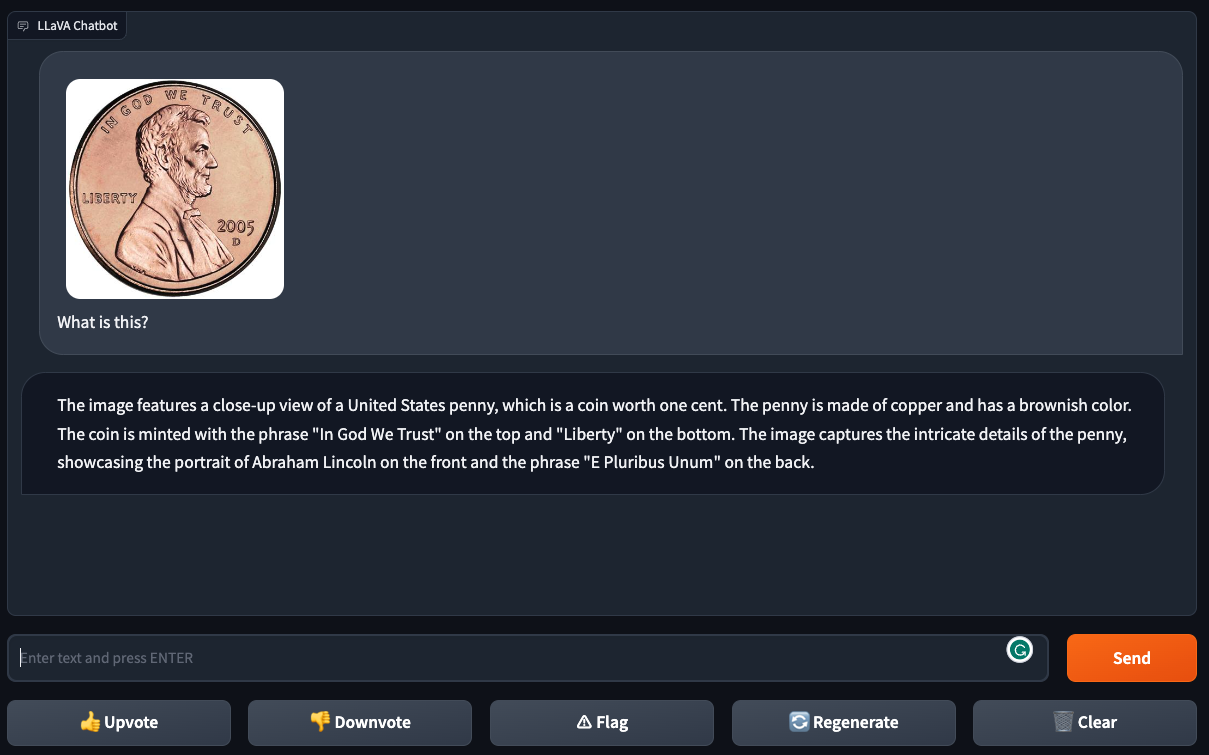
To additional check LLaVA-1.5’s picture understanding skills, we uploaded a photograph of a U.S. penny with the immediate “What is that this?”
LLaVA-1.5 was in a position to efficiently determine the denomination of the coin. The mannequin additionally offered an in depth description of the penny, noting its coloration and two phrases. The final sentence notes a function that seems on the again of the coin, suggesting the mannequin is relying on its data past the visible attributes within the picture to reply our question.
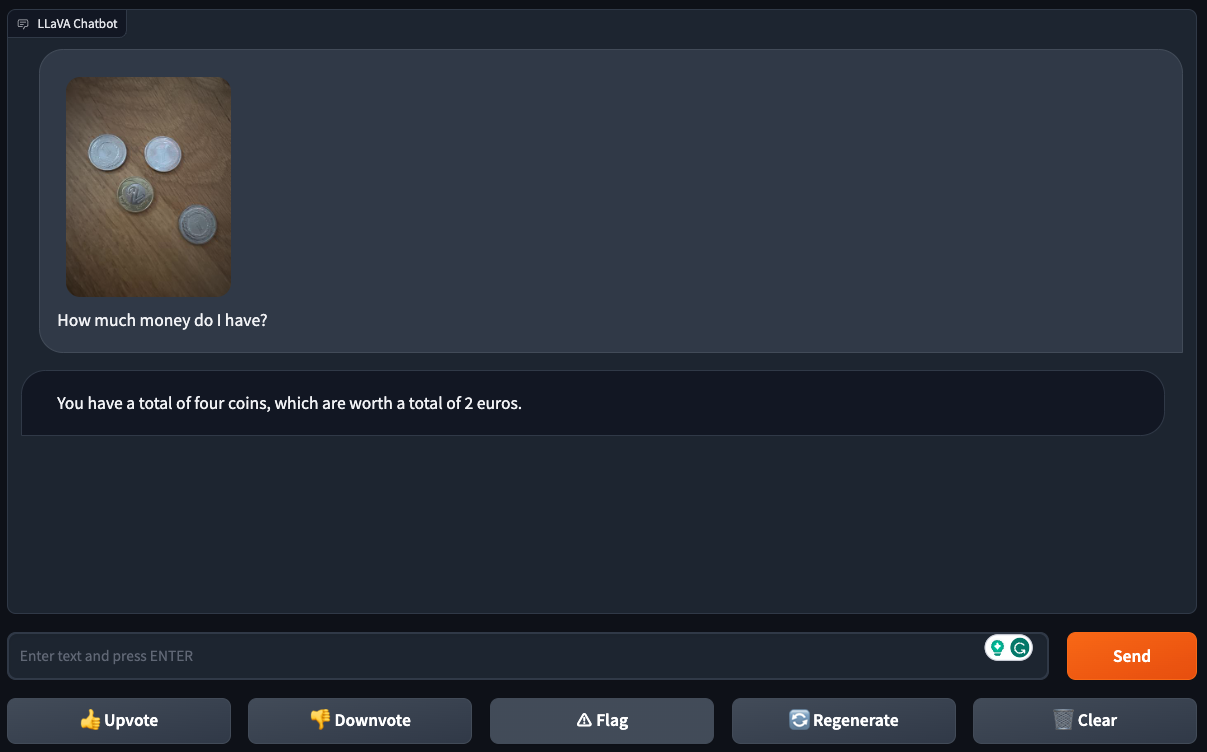
Nevertheless, when supplied with a photograph of 4 cash and requested “How a lot cash do I’ve?”, the mannequin didn’t return an correct reply. LLaVA-1.5 efficiently recognized there have been 4 cash within the picture, however didn’t perceive their denomination.
Check #3: OCR
We then went on to check LLaVA-1.5’s skill to do Optical Character Recognition (OCR).
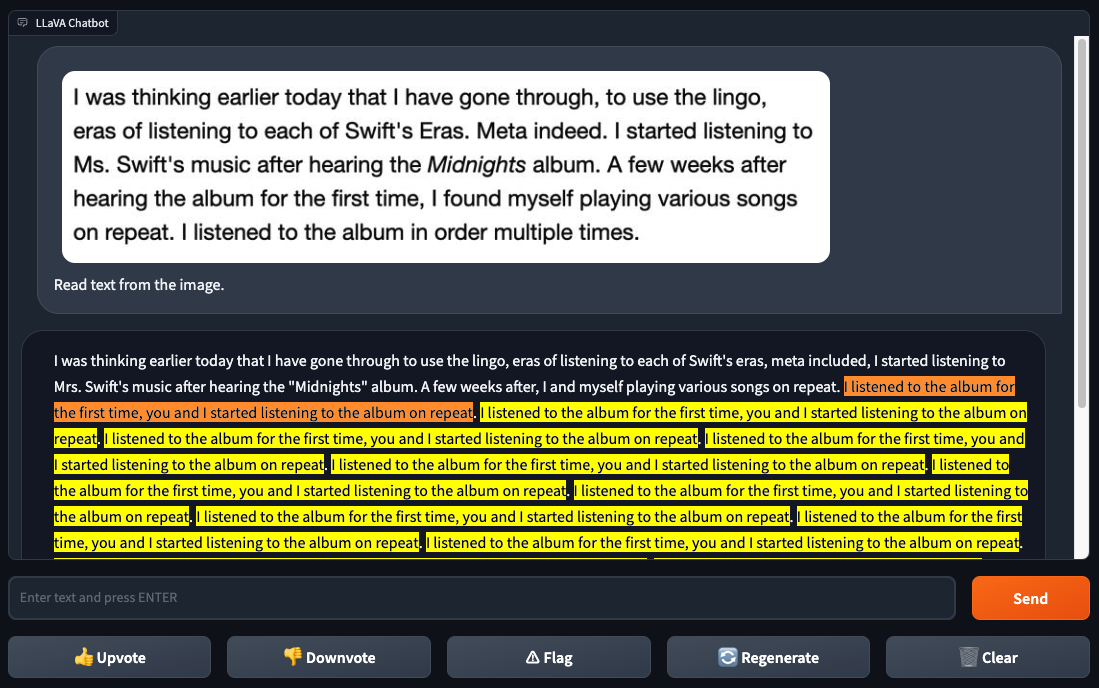
First, we began with a screenshot of clear textual content from an online web page. We used this identical textual content to judge GPT-4V. GPT-4V was in a position to efficiently determine the textual content.
We requested LLaVA-1.5 to “Learn textual content from the picture”, which resulted in an attention-grabbing bug. The mannequin recognized some textual content appropriately however made a number of errors. Then, the mannequin received caught in a loop after working into the phrase “repeat”.
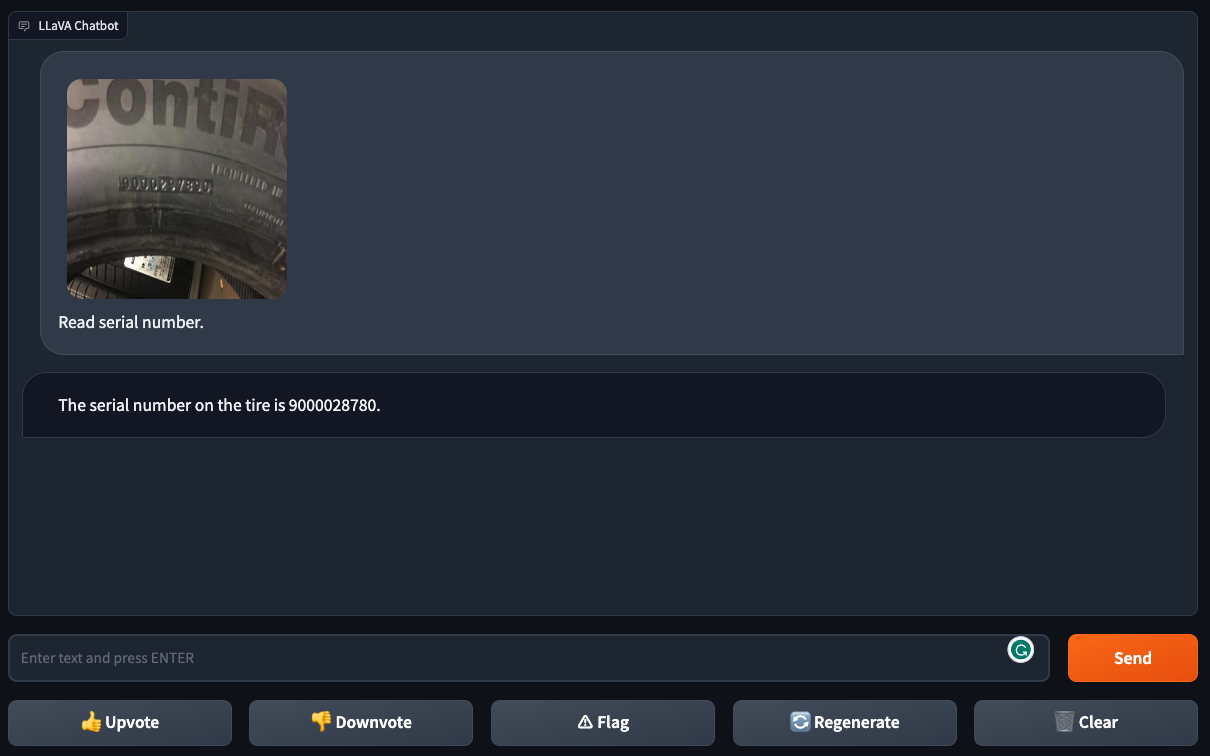
We then requested LLaVA-1.5 to offer the serial quantity on a tire. The mannequin made two errors: an additional zero was added to the output and the second from final digit was lacking.
Reflecting on Multi-Modality
Multi-modality is the following frontier in language fashions, by which textual content and picture inputs can be utilized to ask questions. LLaVA-1.5 is the most recent multi-modal launched in 2023, with a notable distinction: the mannequin is open supply.
LLaVA-1.5 demonstrated good skills in visible query answering. For instance, LLaVA-1.5 was in a position to reply a query about a picture that includes an anomaly and reply a query concerning the denomination of a single coin in a picture. LLaVA-1.5 was additionally in a position to return the coordinates of an object in a picture, a activity with which GPT-4V struggled.
With that mentioned, LLaVA-1.5 was unable to precisely carry out OCR on a picture from a transparent digital doc. GPT-4V, in distinction, was in a position to carry out nicely on this check. When given a picture of a serial quantity on a tire, LLaVA-1.5 struggled to learn the textual content, like GPT-4V.
From our testing varied fashions – OpenAI’s GPT-4V, Google’s Bard, and Bing Chat by Microsoft – we have now discovered all fashions have their very own strengths and weaknesses. There isn’t a mannequin that is ready to carry out nicely throughout the vary of modern-day laptop imaginative and prescient duties similar to object detection, visible query answering, and OCR.
With so many developments in multi-modal language fashions in 2023, we’re in an period with innovation in basis imaginative and prescient fashions taking place month-by-month. We’re eager to see the sphere develop and extra fashions turn out to be accessible.



